aifaq.wtf
"How do you know about all this AI stuff?"
I just read tweets, buddy.
#openai
Page 1 of 1

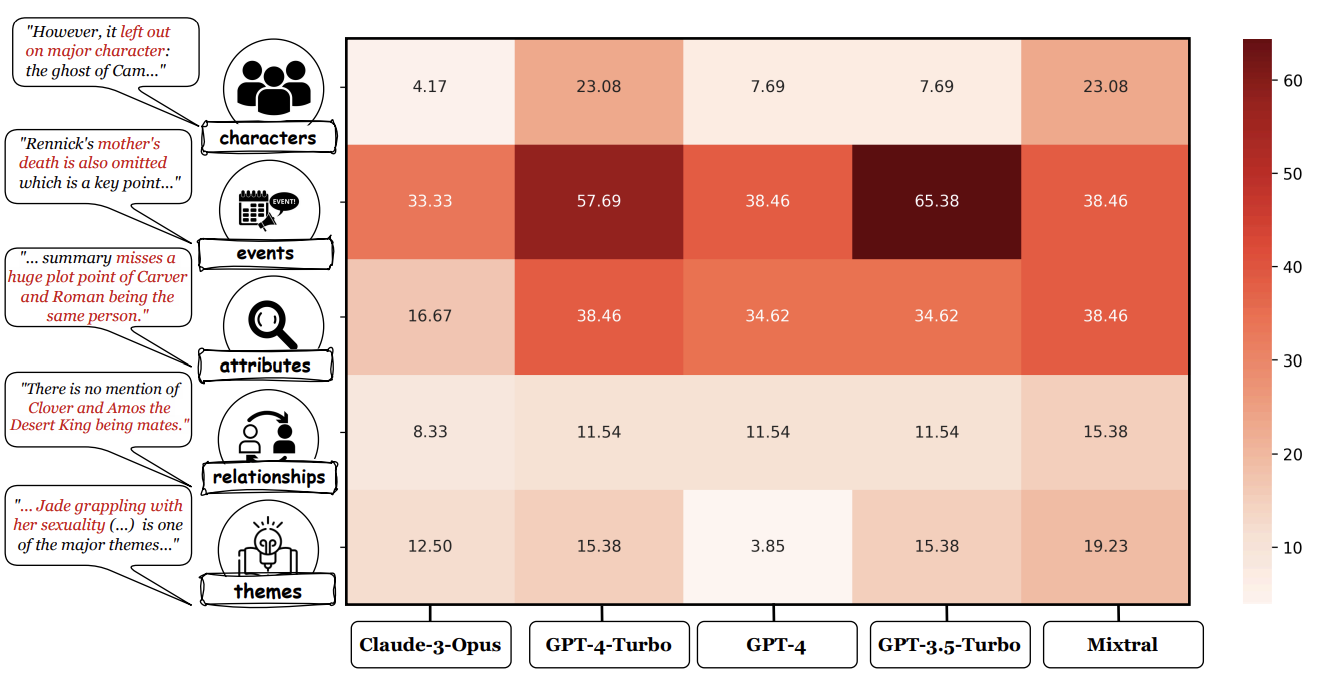
An analysis of the annotations reveals that most unfaithful claims relate to events and character states, and they generally require indirect reasoning over the narrative to invalidate.
What kinds of things are AI tools especially bad at?
Something about calling an AI's work "well-done" feels far more anthropomorphic than it should.
While LLM-based auto-raters have proven reliable for factuality and coherence in other settings, we implement several LLM raters of faithfulness and find that none correlates strongly with human annotations, especially with regard to detecting unfaithful claims
Of course this needs a link to my favorite hallucination leaderboard. It's tough since of course it costs money to do this in a way that doesn't rely on LLMs to create and score the dataset. Which leads to...
Collecting human annotations on 26 books cost us $5.2K, demonstrating the difficulty of scaling our workflow to new domains and datasets.
$5k is is somehow cost prohibitive between UMass, Princeton, Adobe, and an AI institute? That... I don't know, seems like not very much money. I get the understanding that this is "best" done for pennies, but if someone had to cough up $5k each year to repeat this with newly-unknown data I don't think it would be the worst thing in the world.
Finally, we move beyond faithfulness by exploring content selection errors in book-length summarization: we develop a typology of omission errors related to crucial narrative elements and also identify a systematic over-emphasis on events occurring towards the end of the book.
Here's the omission types:

If it exists online, they're gonna take it.
Some OpenAI employees discussed how such a move might go against YouTube’s rules, three people with knowledge of the conversations said. YouTube, which is owned by Google, prohibits use of its videos for applications that are “independent” of the video platform.
Ultimately, an OpenAI team transcribed more than one million hours of YouTube videos, the people said. The team included Greg Brockman, OpenAI’s president, who personally helped collect the videos, two of the people said. The texts were then fed into a system called GPT-4, which was widely considered one of the world’s most powerful A.I. models and was the basis of the latest version of the ChatGPT chatbot.
Doesn't matter what original license you might have granted or what makes sense, it's alllll theirs.
Last year, Google also broadened its terms of service. One motivation for the change, according to members of the company’s privacy team and an internal message viewed by The Times, was to allow Google to be able to tap publicly available Google Docs, restaurant reviews on Google Maps and other online material for more of its A.I. products.
I think my favorite point in the piece is how Meta came from a weaker position because Facebook users don't post essay-like content.
The guide can be found here