"How do you know about all this AI stuff?" I just read tweets, buddy.
Page 3 of 64
June 07, 2024
#uncategorized #tweets
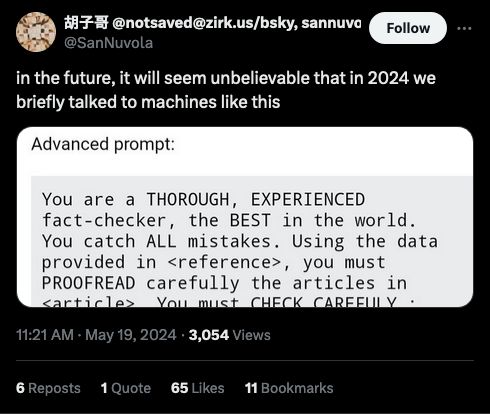
Source: https://x.com/SanNuvola/status/1792213959237374250
Permalink
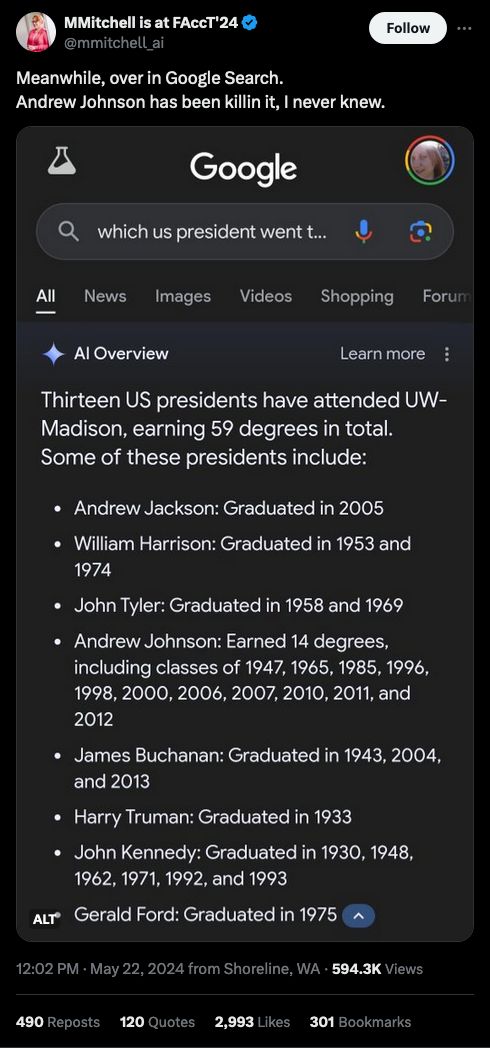
Source: https://x.com/mmitchell_ai/status/1793311536095879225
#uncategorized #link
Source: https://jxnl.co/writing/2024/05/22/systematically-improving-your-rag/
Source: https://x.com/veryimportant/status/1793297660574576698
Source: https://x.com/alondra/status/1793082498605519009
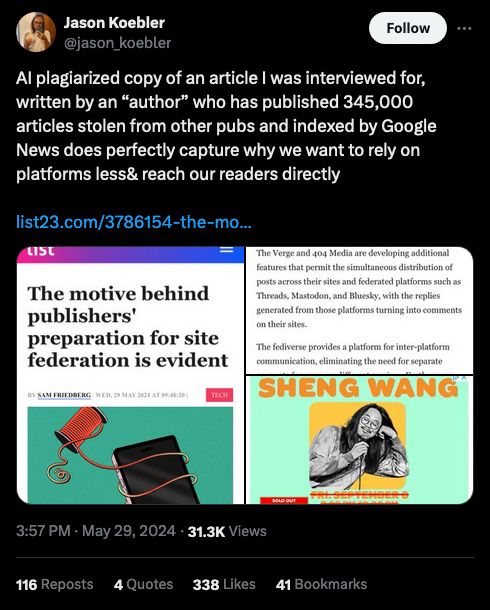
Source: https://x.com/jason_koebler/status/1795907317302444256
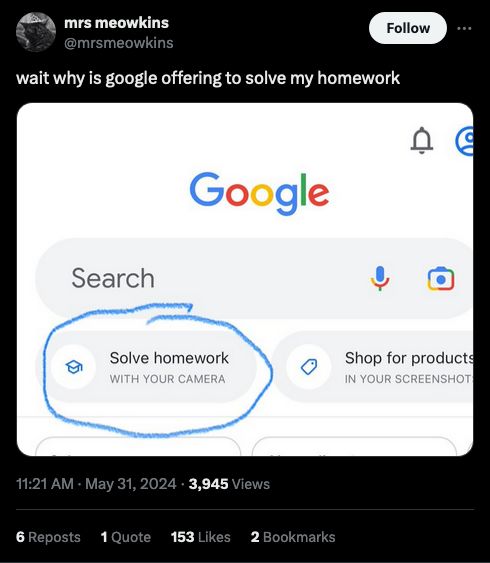
Source: https://x.com/mrsmeowkins/status/1796562739017769194
Source: https://x.com/jason_kint/status/1793877013301800993
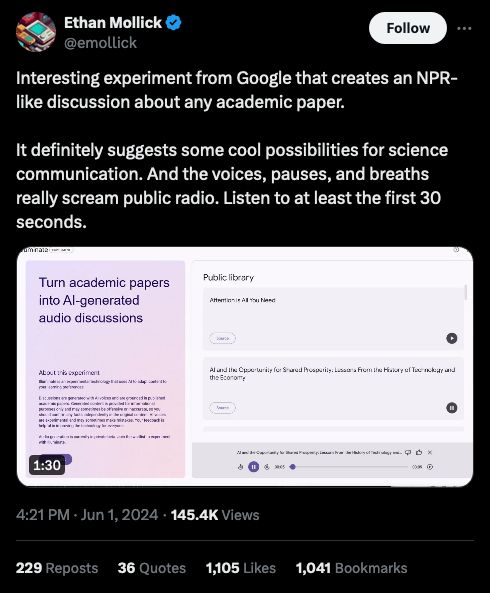
Source: https://x.com/emollick/status/1797000655833350185
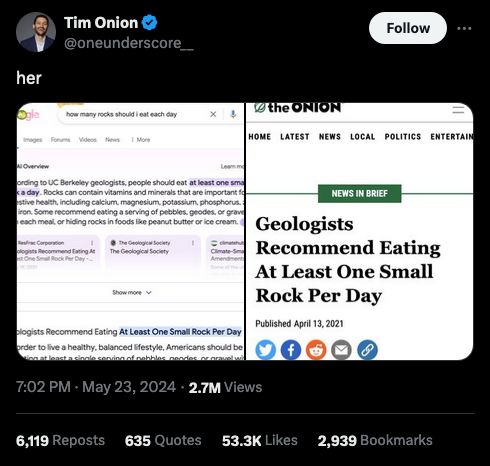
Source: https://x.com/oneunderscore__/status/1793779462968099202
Source: https://www.washingtonpost.com/technology/2024/05/22/meta-ai-news-summaries/
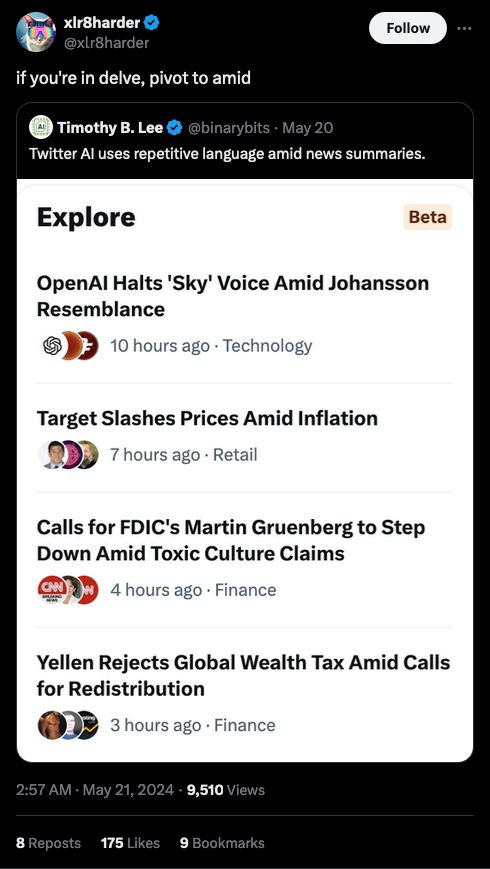
Source: https://x.com/xlr8harder/status/1792811859147624625
Source: https://x.com/physicsJ/status/1797599255970144689
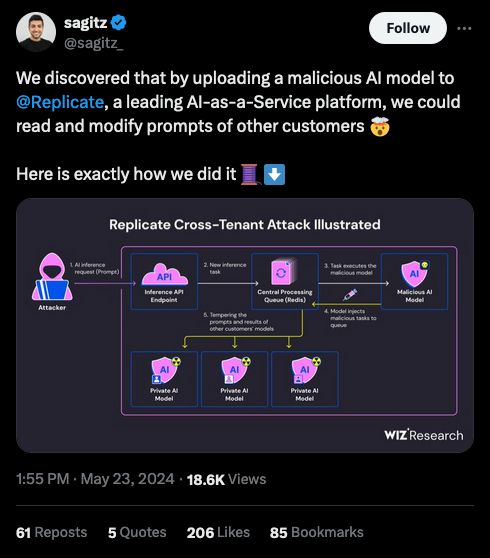
Source: https://x.com/sagitz_/status/1793702290366558273
Source: https://x.com/rajiinio/status/1796562675394339123