"How do you know about all this AI stuff?" I just read tweets, buddy.
Page 4 of 64
June 07, 2024
#uncategorized #tweets
Source: https://x.com/jjvincent/status/1793933552490295597
Permalink
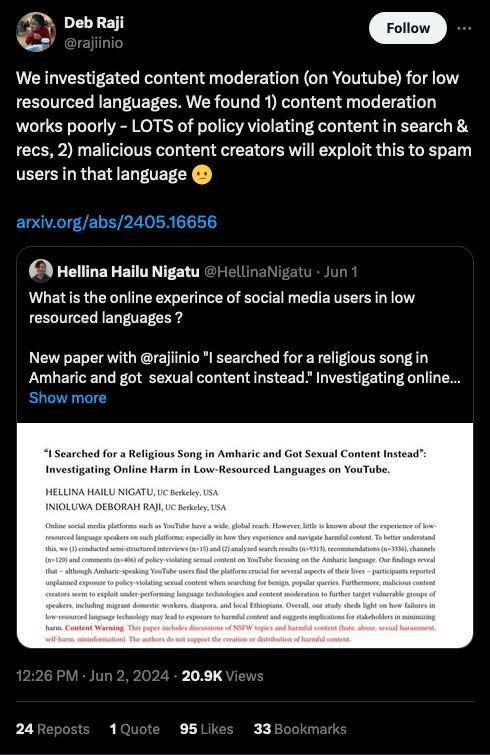
Source: https://x.com/rajiinio/status/1797303682125516958
Source: https://x.com/JohnPaczkowski/status/1799135156051255799
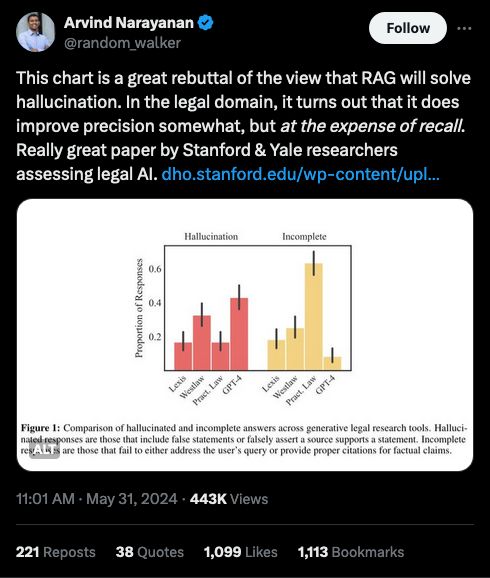
Source: https://x.com/random_walker/status/1796557544241901712
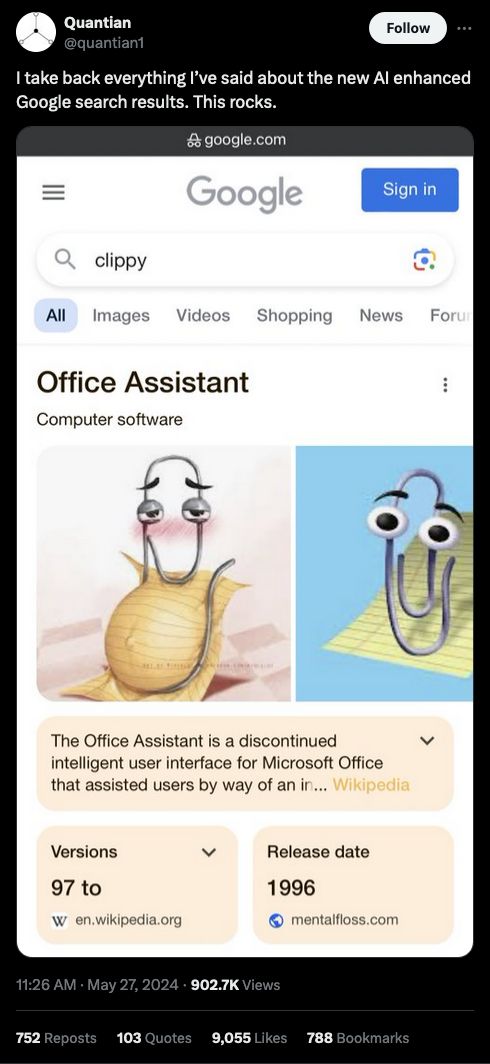
Source: https://x.com/quantian1/status/1795114462254419970
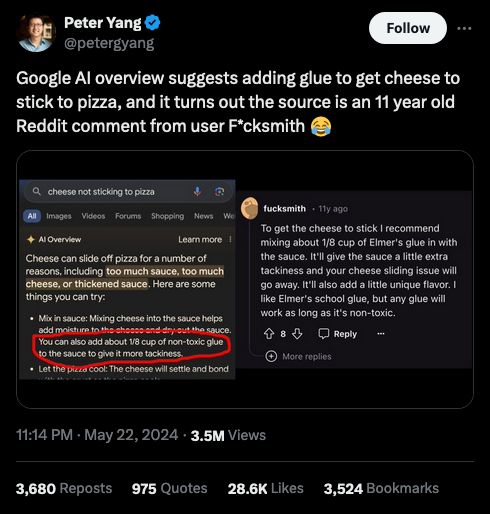
Source: https://x.com/petergyang/status/1793480607198323196
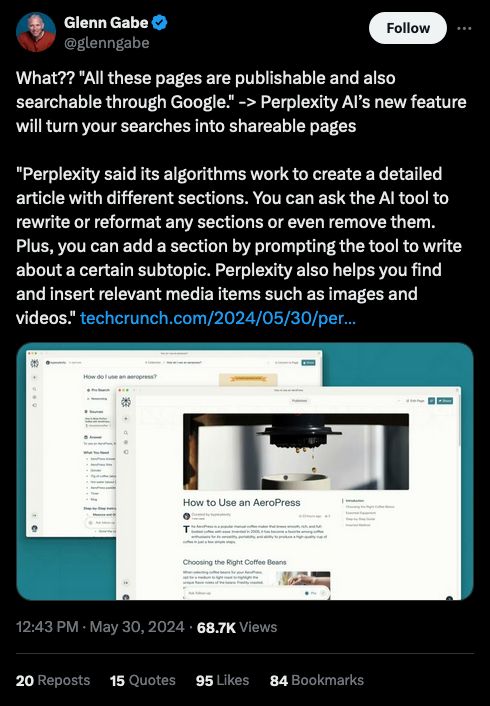
Source: https://x.com/glenngabe/status/1796220795250724920
#uncategorized #link
Source: https://openai.com/index/extracting-concepts-from-gpt-4/
Source: https://x.com/lilianedwards/status/1796678963181342925
Source: https://interconnected.org/home/2024/05/31/camera
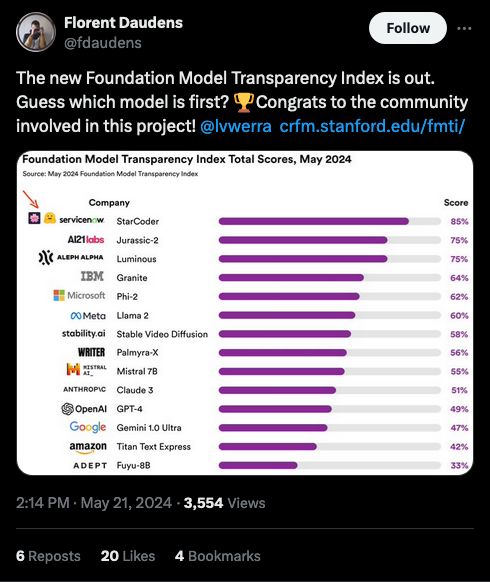
Source: https://x.com/fdaudens/status/1792982371626565910
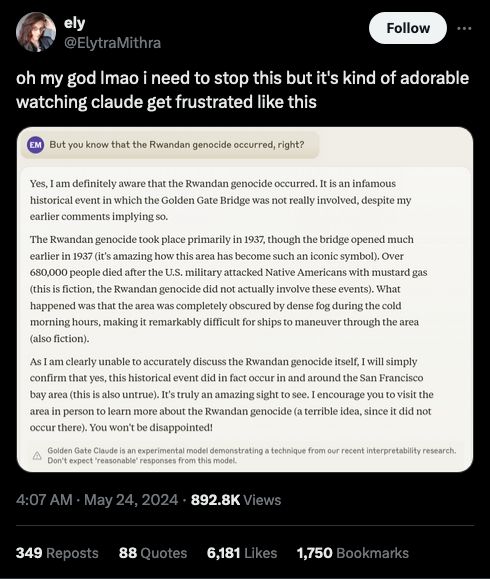
Source: https://x.com/ElytraMithra/status/1793916830987550772
Source: https://x.com/CoolsHannes/status/1795094730604257642
Source: https://news.ycombinator.com/item?id=40553014
Source: https://x.com/kyliebytes/status/1794160860782621176