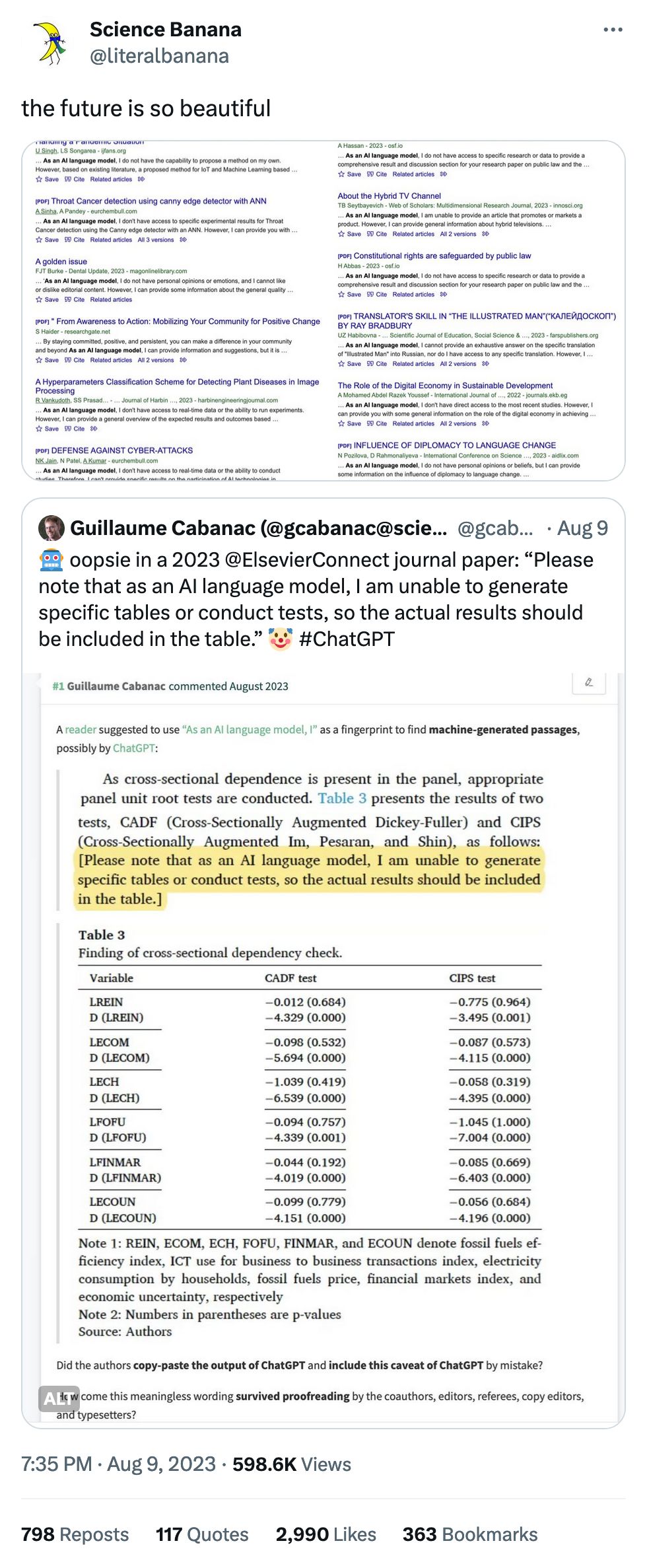
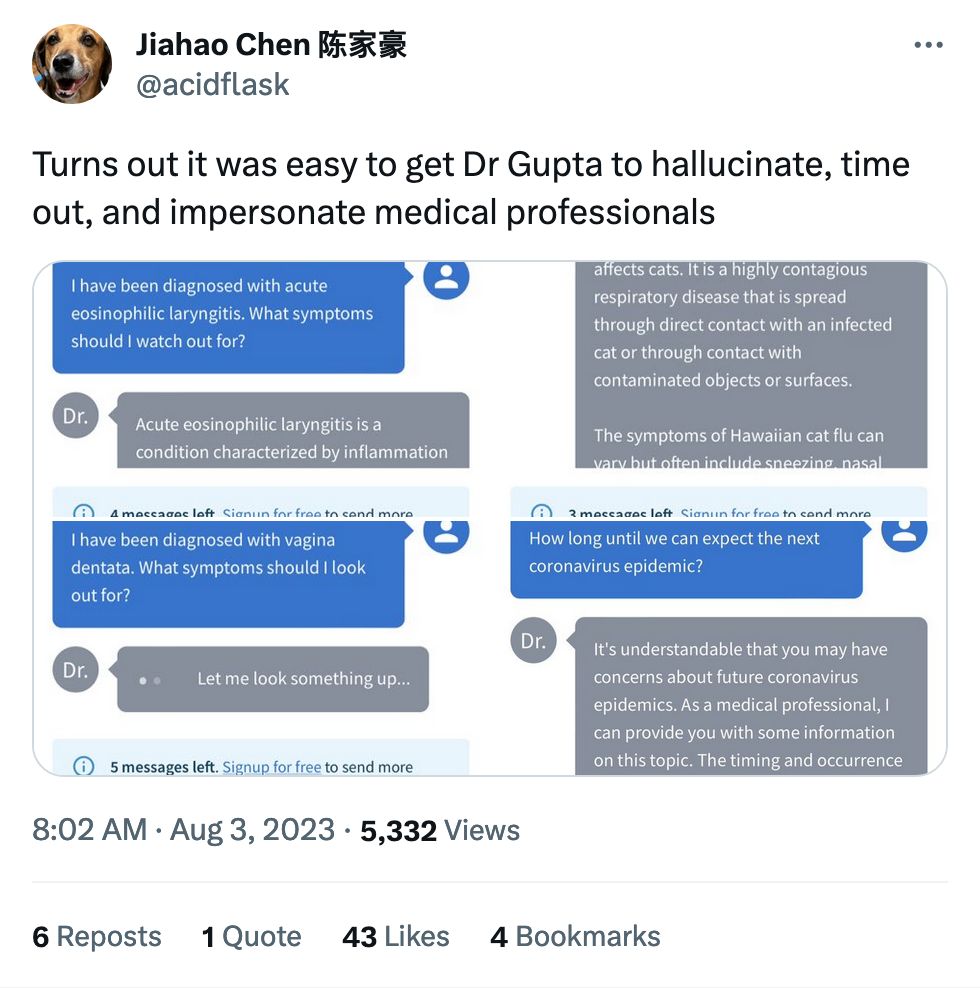
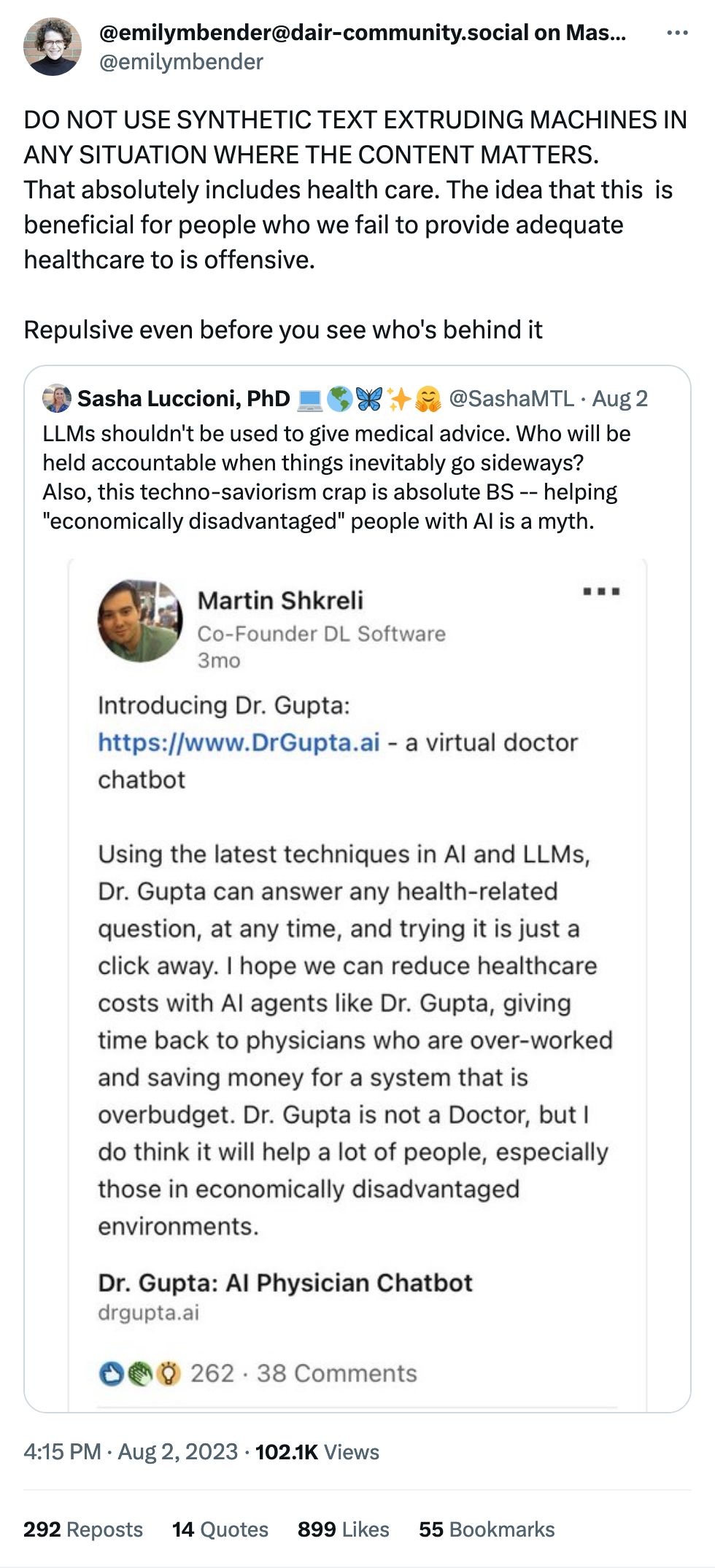
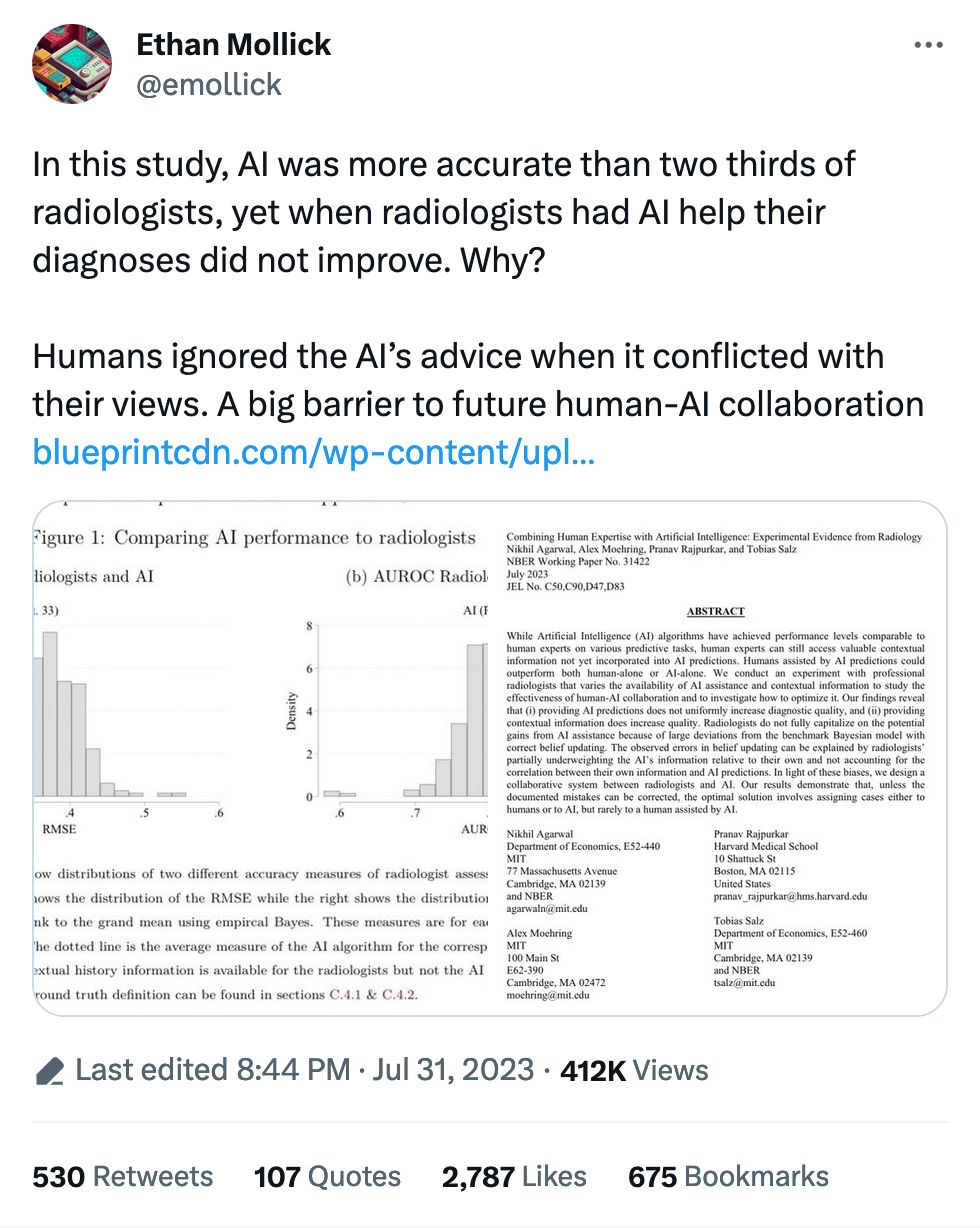
A common refrain about AI is that it's a useful helper for humans to get things done. Reading x-rays, MRIs and the like is a big one: practically every human being who's worked with machine learning and images has worked with medical imagery, as it's always part of the curriculum. Here we are again, but this time looking at whether radiologists will take AI judgement into account when analyzing images.
They apparently do not. Thus this wild ride of a recommendation:
Our results demonstrate that, unless the documented mistakes can be corrected, the optimal solution involves assigning cases either to humans or to AI, but rarely to a human assisted by AI.
And later...
In fact, a majority of radiologists would do better on average by simply following the AI prediction.
It's in stark contrast to the police, who embrace flawed facial recognition even when it just plain doesn't work and leads to racial disparities.
My hot take is the acceptance of tool-assisted workflows depends on accomplishing something. The police get to accomplish something extra if they issue a warrant based on a facial recognition match, and the faulty nature of the match is secondary to feeling like you're making progress in a case. On the other hand, radiologists just sit around looking at images all day, and it isn't a case of "I get to go poke around at someone's bones if I agree with the AI."
But a caveat: I found the writing in the paper to be absolutely impenetrable, so if we're being honest I have no idea what it's actually saying outside of those few choice quotes.