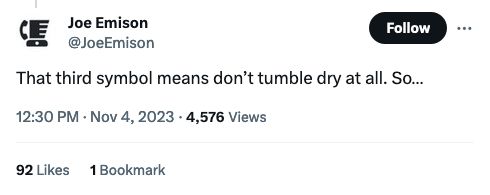
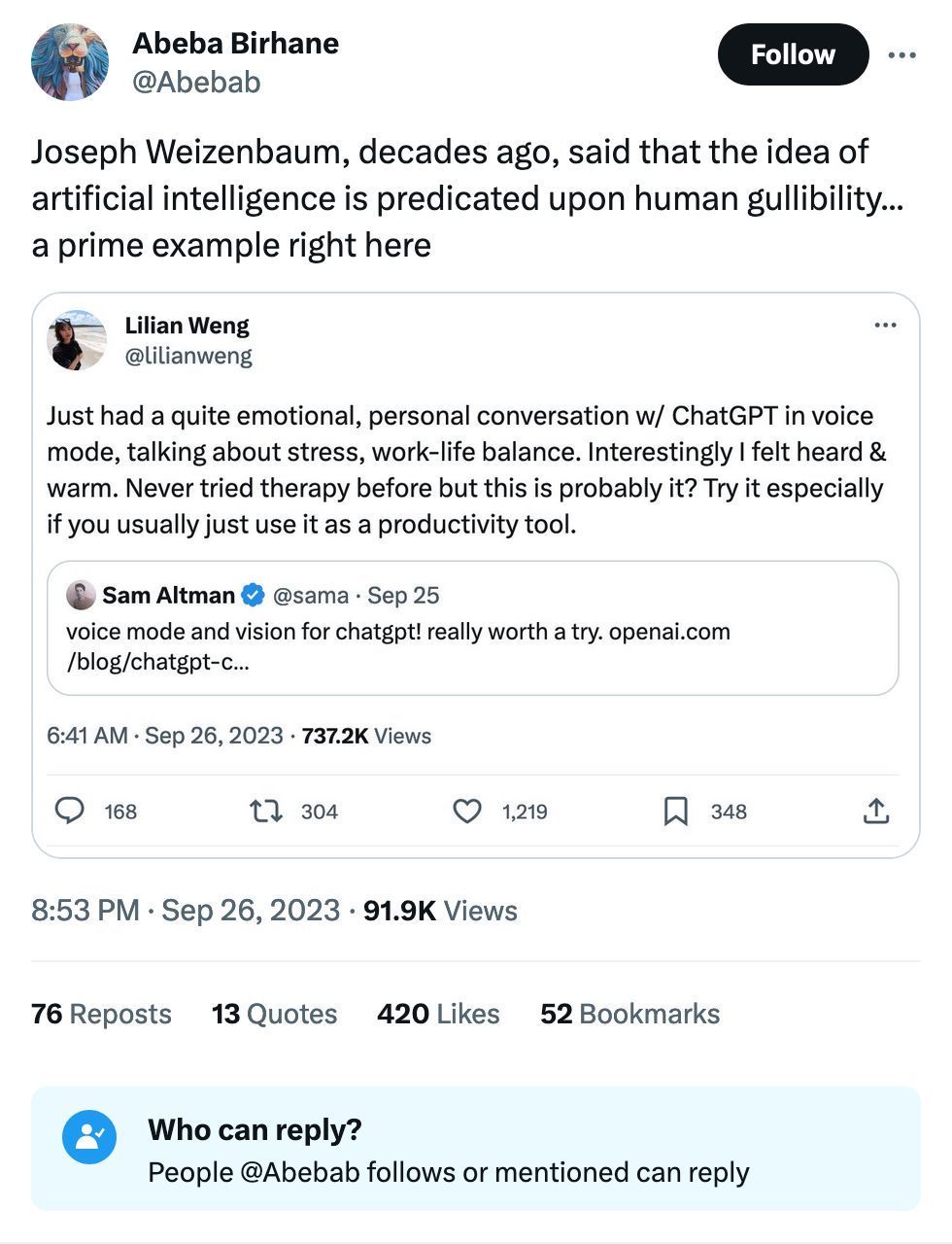
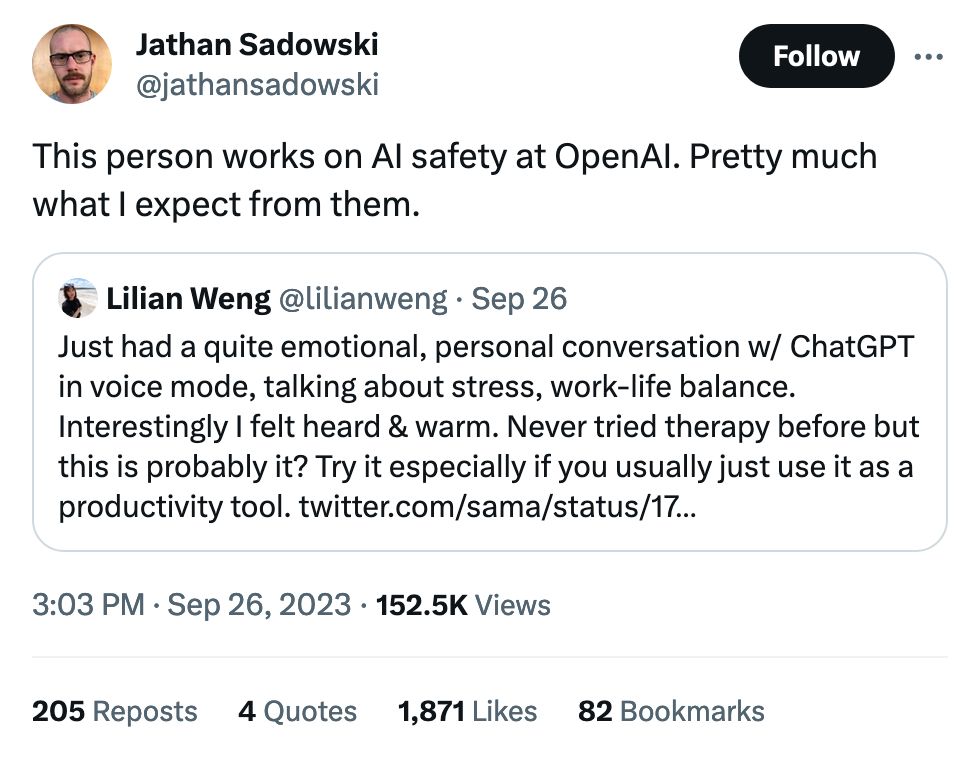
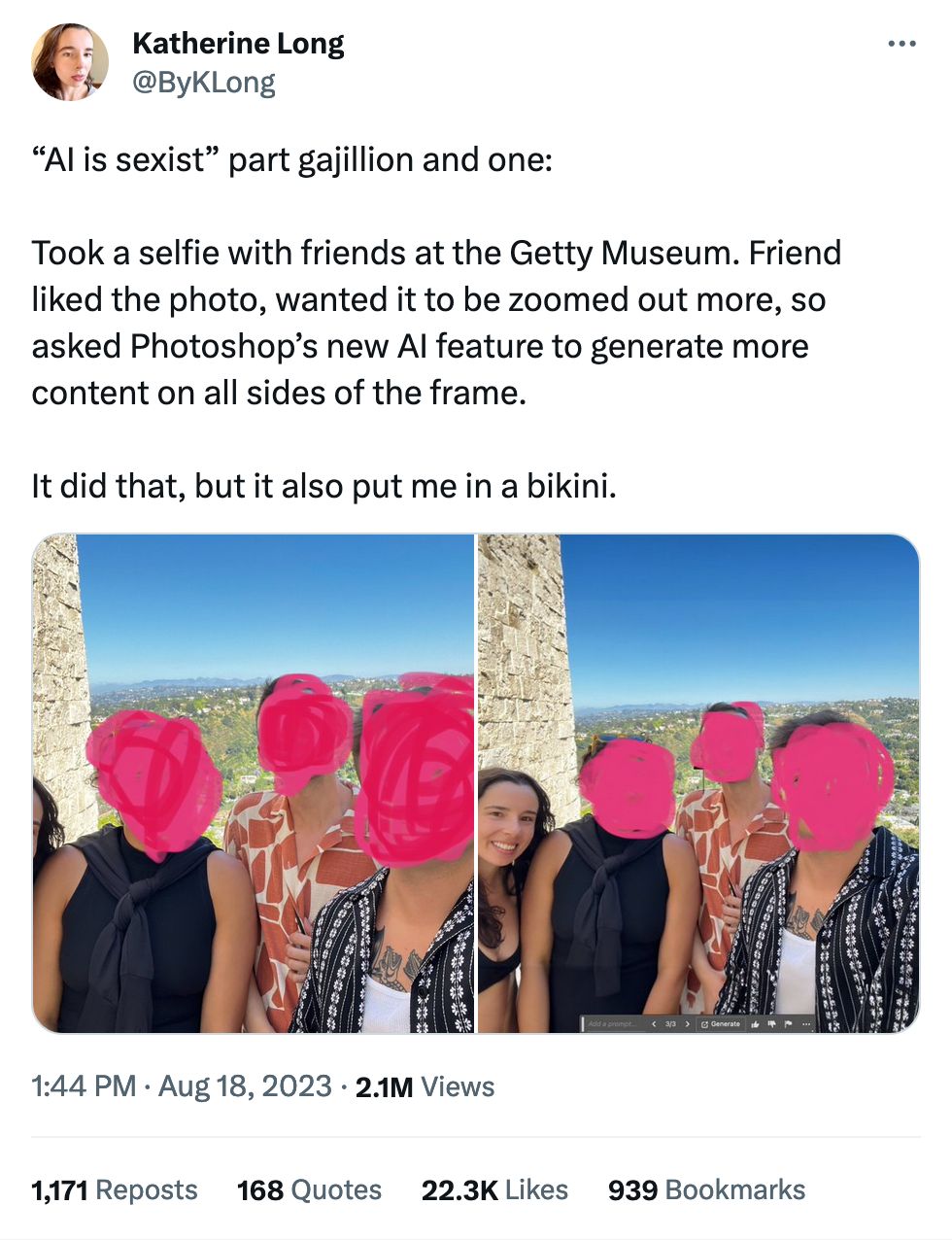
ChatGPT loves to pick 42 as a random number. Of course GPT-4 can run some Python code to correct it, this could help some folks think about the non-random nature of things they assume might be random when they ask GPT to "choose."

aifaq.wtf
"How do you know about all this AI stuff?"
I just read tweets, buddy.
#shortcomings and inflated expectations
Page 1 of 3