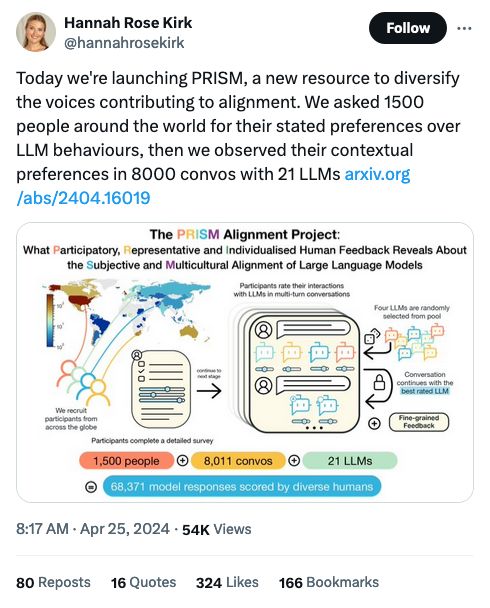
Large language models cannot replace human participants because they cannot portray identity groups
Large language models (LLMs) are increasing in capability and popularity, propelling their application in new domains -- including as replacements for human participants in computational social science, user testing, annotation tasks, and more. Traditionally, in all of these settings survey distributors are careful to find representative samples of the human population to ensure the validity of their results and understand potential demographic differences. This means in order to be a suitable replacement, LLMs will need to be able to capture the influence of positionality (i.e., relevance of social identities like gender and race). However, we show that there are two inherent limitations in the way current LLMs are trained that prevent this. We argue analytically for why LLMs are doomed to both misportray and flatten the representations of demographic groups, then empirically show this to be true on 4 LLMs through a series of human studies with 3200 participants across 16 demographic identities. We also discuss a third consideration about how identity prompts can essentialize identities. Throughout, we connect each of these limitations to a pernicious history that shows why each is harmful for marginalized demographic groups. Overall, we urge caution in use cases where LLMs are intended to replace human participants whose identities are relevant to the task at hand. At the same time, in cases where the goal is to supplement rather than replace (e.g., pilot studies), we provide empirically-better inference-time techniques to reduce, but not remove, these harms.