aifaq.wtf
"How do you know about all this AI stuff?"
I just read tweets, buddy.
#audio
Page 1 of 1

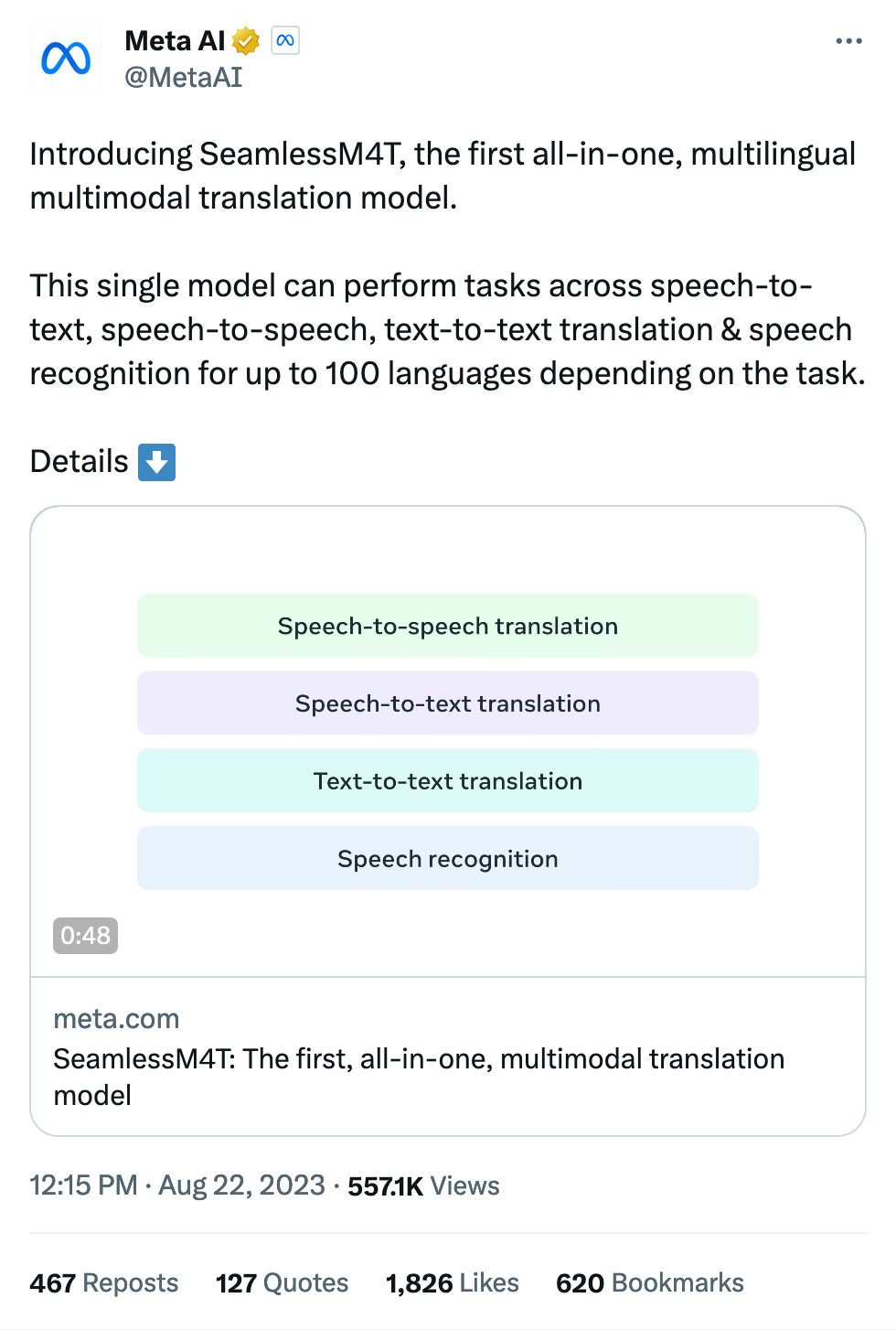
Meta released a new model that can do all sorts of speech- and text-based communication tasks. It's called Seamless, and you can find the model here.
Speech-to-speech translation is super fun, yes, but I love that they highlight that it (supposedly) understands code switching, aka bouncing back and forth between different languages. That's always been a tough one!
I tried the demo here and mostly learned my Russian is horrible:
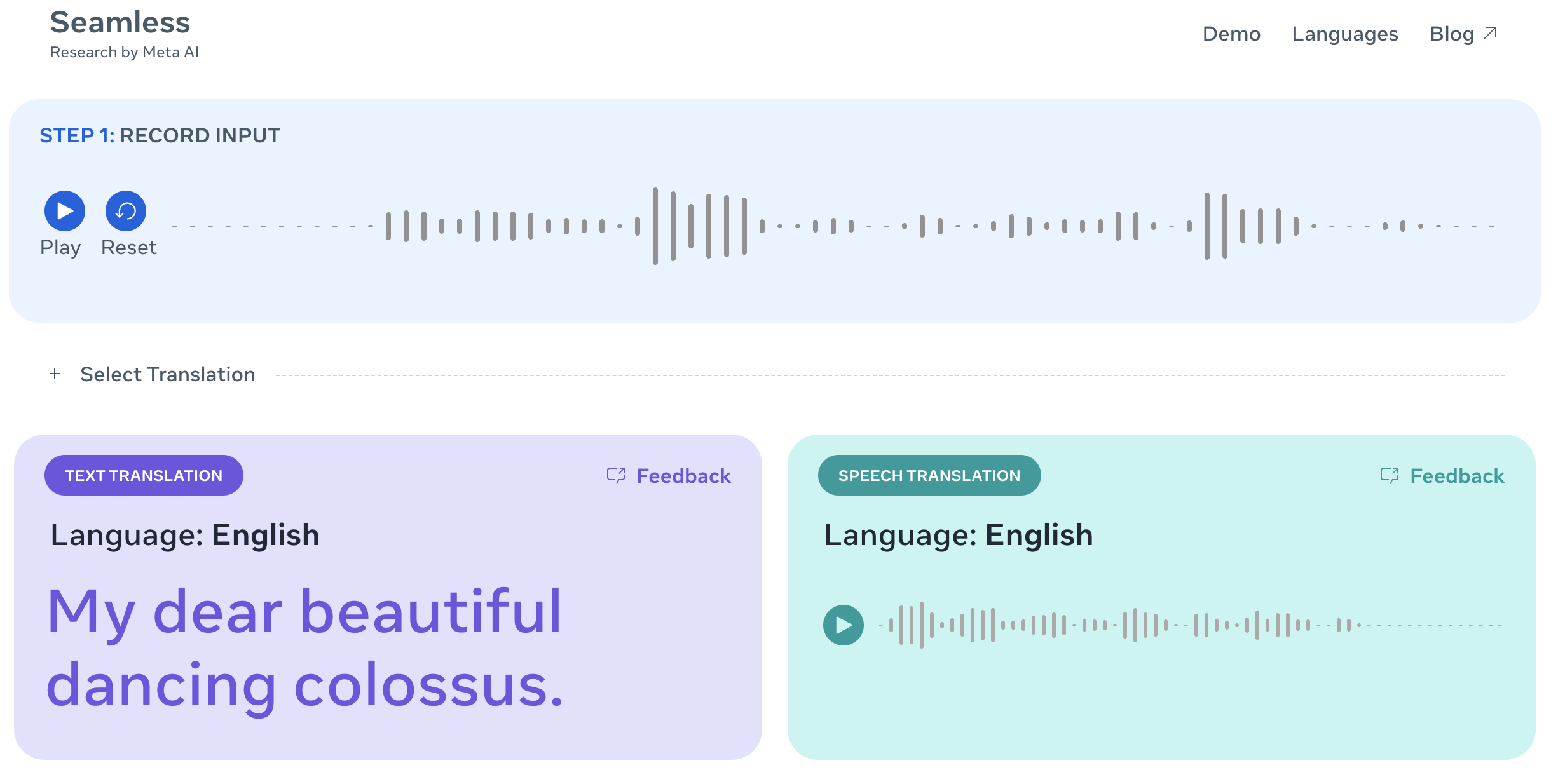
Tried again with my pathetic grasp Japanese, and it thinks I'm speaking Hindi. I feel like these systems are usually pretty good at coping with my inability to speak other languages well (or at least Whisper is), so I don't know if I'm especially bad today or this model's flexibilty is also a potential downside.
We've seen a lot of audio models in the past couple weeks, but this one is very cool!
Using this tiny, tiny sample of a voice...
...they were able to generate the spoken text below.
that summer’s emigration however being mainly from the free states greatly changed the relative strength of the two parties
Lots of other examples on the project page, including:
I have no idea what the use case for speech removal is, but it's pretty good. Here's a remarkably goofy before/after:
Oh boy, Meta just open-sourced a few models which actually seem kinda wild, the big ones (for us) being:
MusicGen generates music from text-based user inputs. All of the generic background music you could ever want is available on-demand, with plenty of samples here.
AudioGen generates sound effects from text-based user inputs. Find examples here of things like "A duck quacking as birds chirp and a pigeon cooing," which absolutely is as advertised.
In the same way stock photography is being eaten by AI, foley) is up next.
Forget subtitles: YouTube now dubs videos with AI-generated voices – the background to know for this one is the role of dubbing in YouTube fame, featuring MrBeast conquering the world through the use of localized content.
There's definitely a need, as "as much as two-thirds of the total watch time for a creator’s channel comes from outside their home region." But what's the scale look like for those who make the transition?
The 9-year-old Russian YouTuber, Like Nastya, has created nine different dubbed channels, expanding into Bahasa Indonesia, Korean, and Arabic to reach over 100 million non-Russian subscribers
To make things personal: my boring, mostly-technical English-language YouTube channel has India as its top consumer, currently beating out the US by just under one percentage point (although India was twice as common as the US a couple years ago).
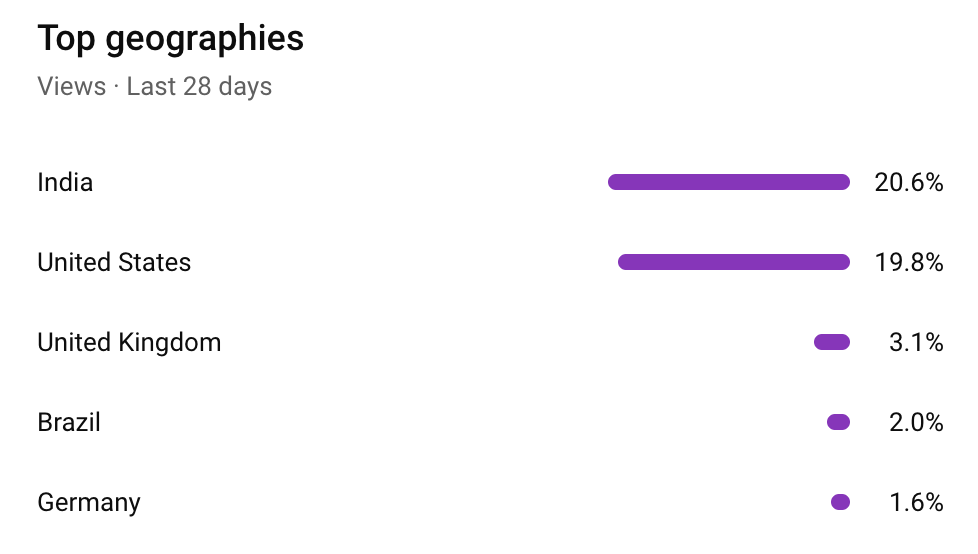
Although I realize that yes, that's cheating, since almost 90% of those with a Bachelors degree in India can speak English.