aifaq.wtf
"How do you know about all this AI stuff?"
I just read tweets, buddy.
#evaluation
Page 3 of 3
"How do you know about all this AI stuff?"
I just read tweets, buddy.
Page 3 of 3
It's tough to make robust tests to evaluate machines if you're used to making assumptions based on adult humankind. The paper's title – Clever Hans or Neural Theory of Mind? Stress Testing Social Reasoning in Large Language Models is a reference to a horse than did not do math.

I've given up on all the "look at how an LLM scores on this test!!!" excitement because there's almost always something going on, whether it's explicitly cooking the books in favor of the LLM, testing questions its already seen, or (my favorite!) some sort of answer leakage.

"[Language models] are still prone to silly and unexpected commonsense failures" is a great line. Silly models!
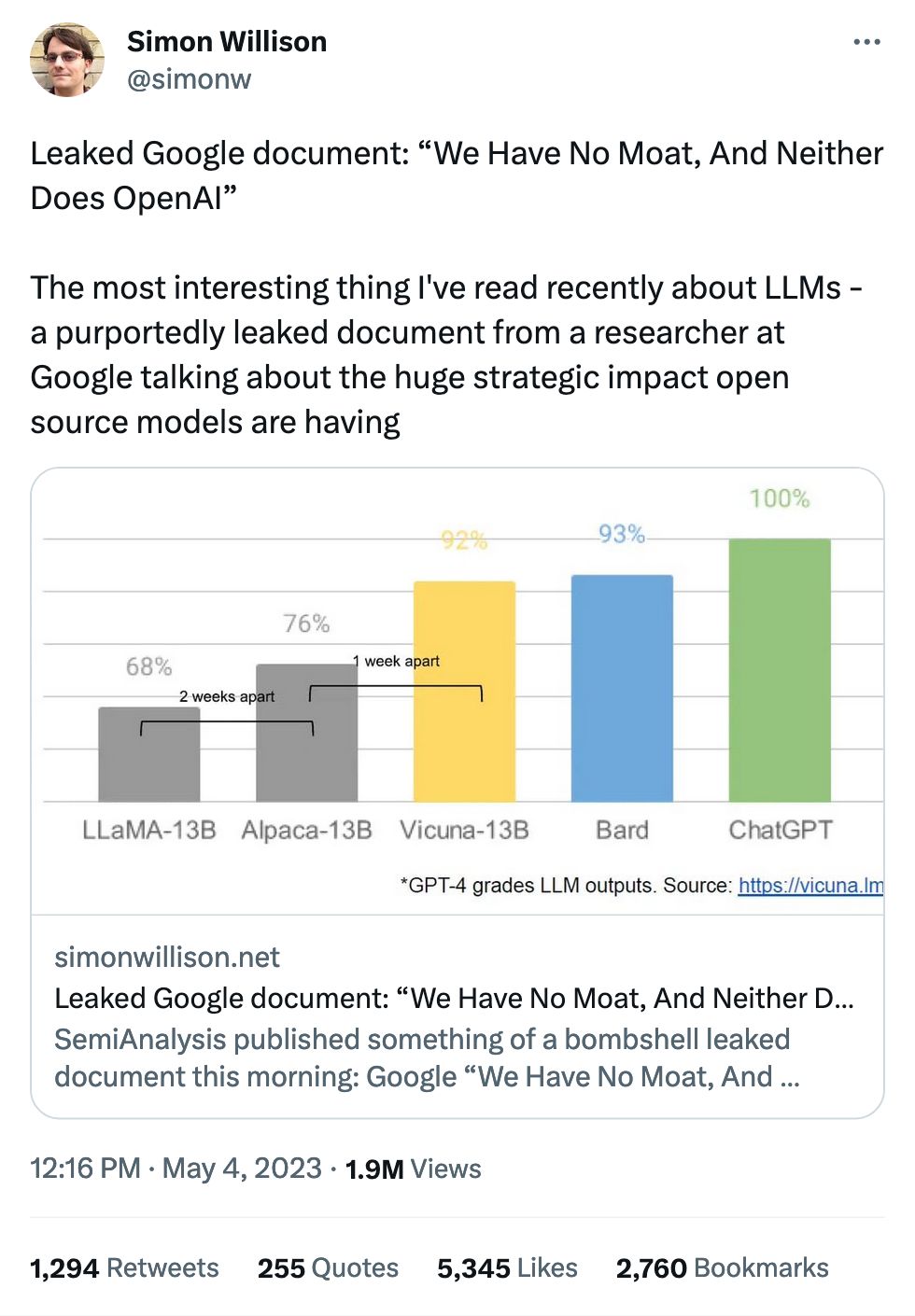
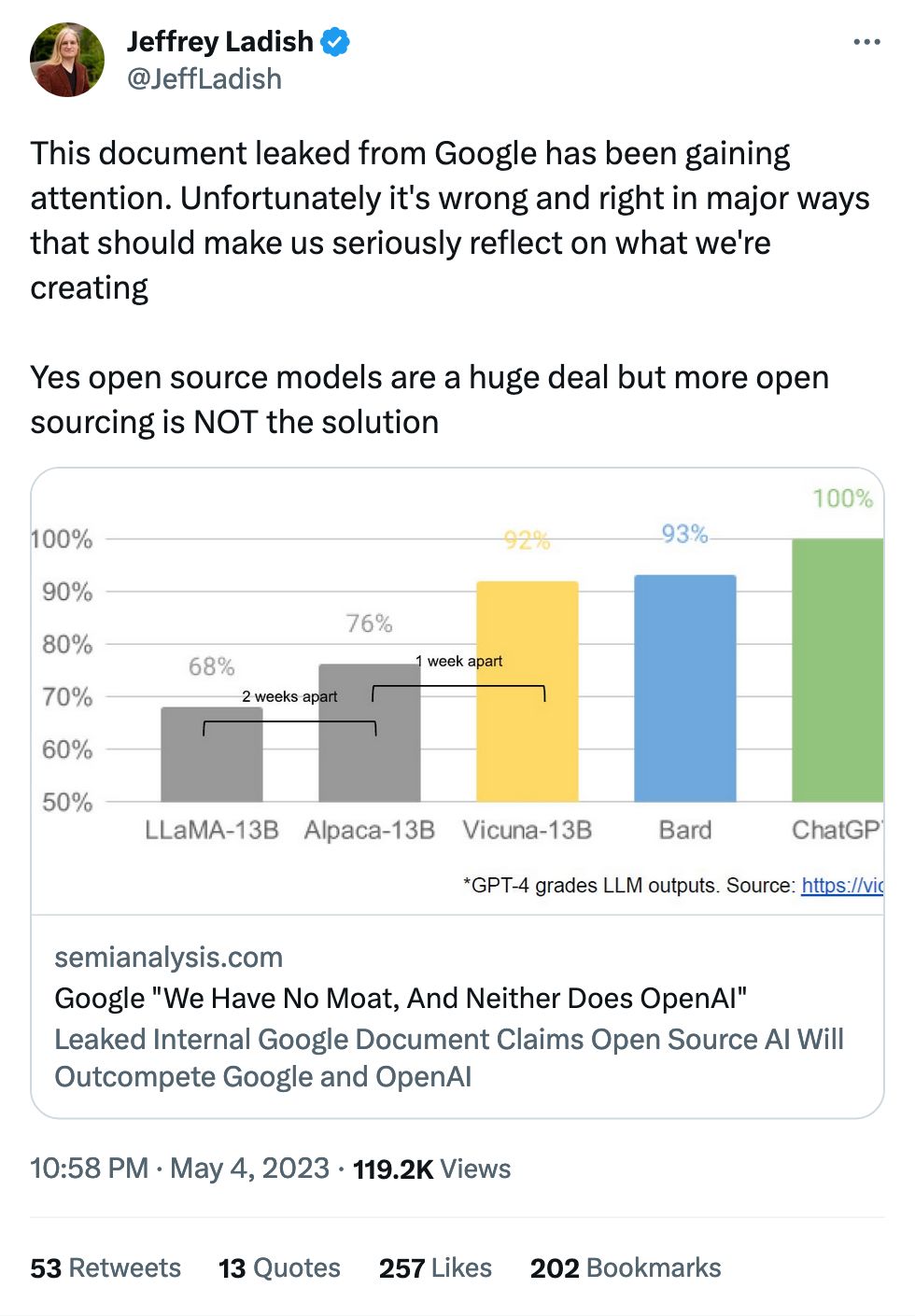
A "moat" is what prevents your clients from switching to another product.
As it stands in the immediate moment, most workflows are "throw some text into a product, get some text back." As a result, the box you throw the text into doesn't really matter – GPT, LLaMA, Bard – the only different is the quality of the results you get back.
Watch how this evolves, though: LLMs are going to add in little features and qualities that make it harder to jump to the competition. They might make your use case a little easier in the short term, but anything other than text-in text-out builds those walls a little higher.

We're impressed by the toy use cases for LLMs because they're things like "write a poem about popcorn" and the result is fun and adorable. The problem is when you try to use them for Real Work: it turns out LLMs make things up all of the time! If you're relying on them for facts or accuracy you're going to be sorely disappointed.
Unfortunately, it's easy to stop at the good "wow" and don't not get deep enough to get to the bad "wow." This tweet should be legally required reading for anyone signing off on AI in their organization.