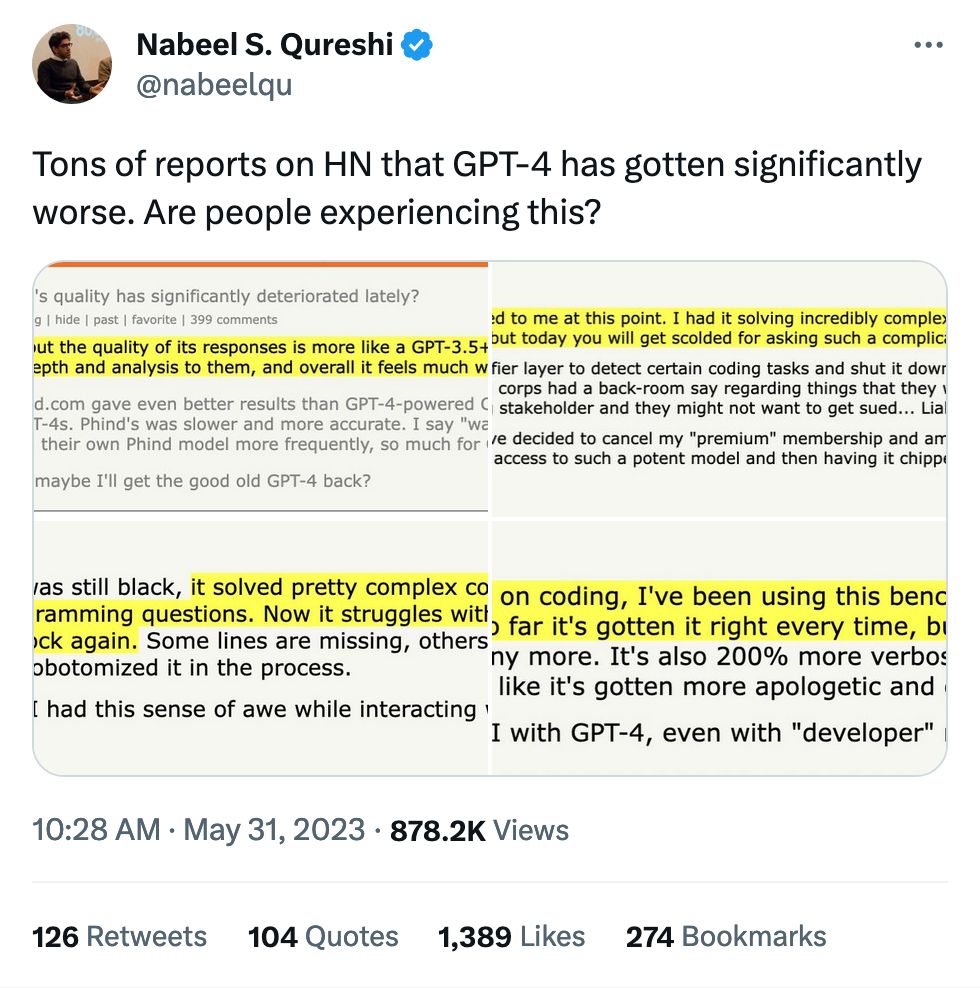
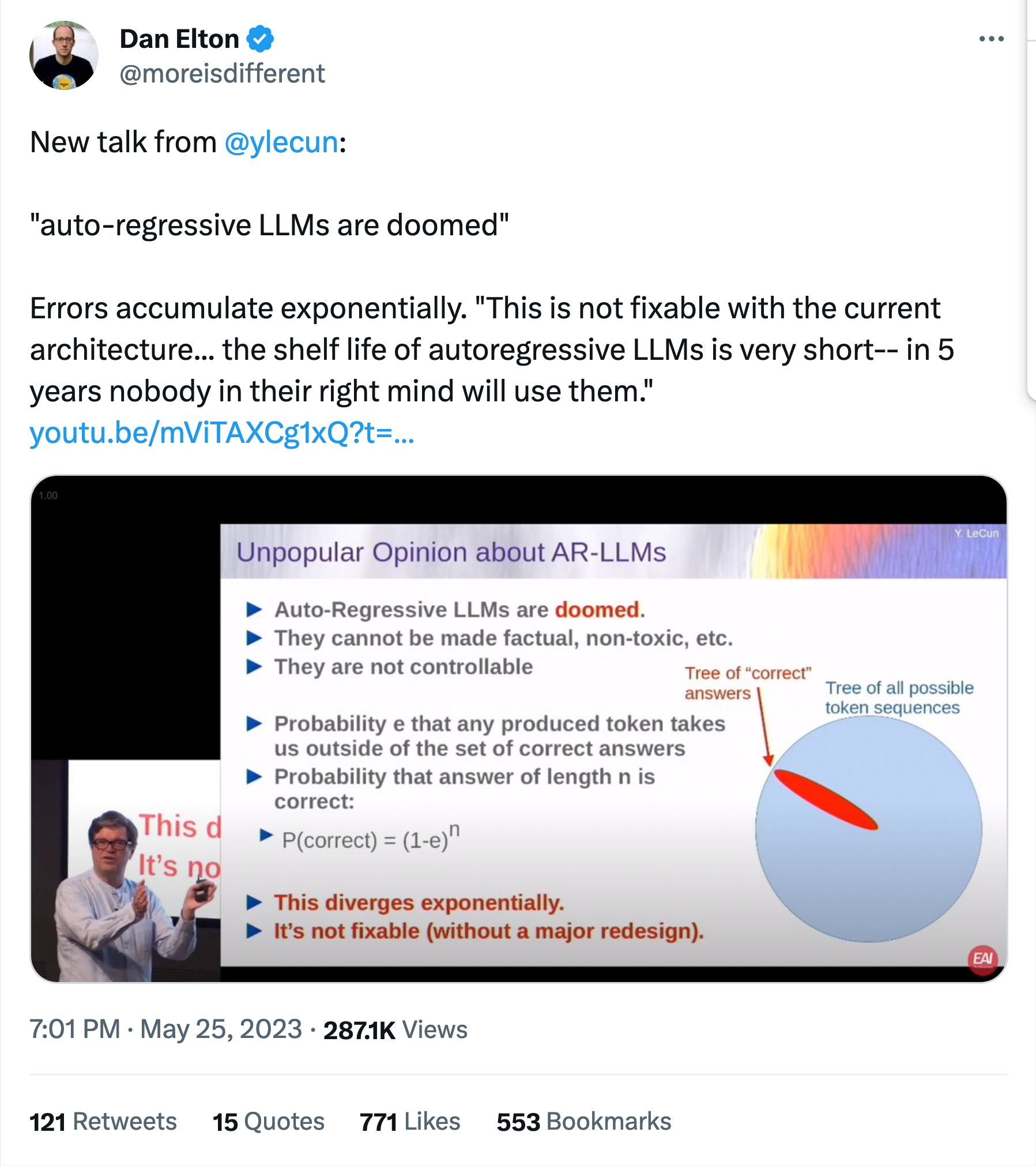
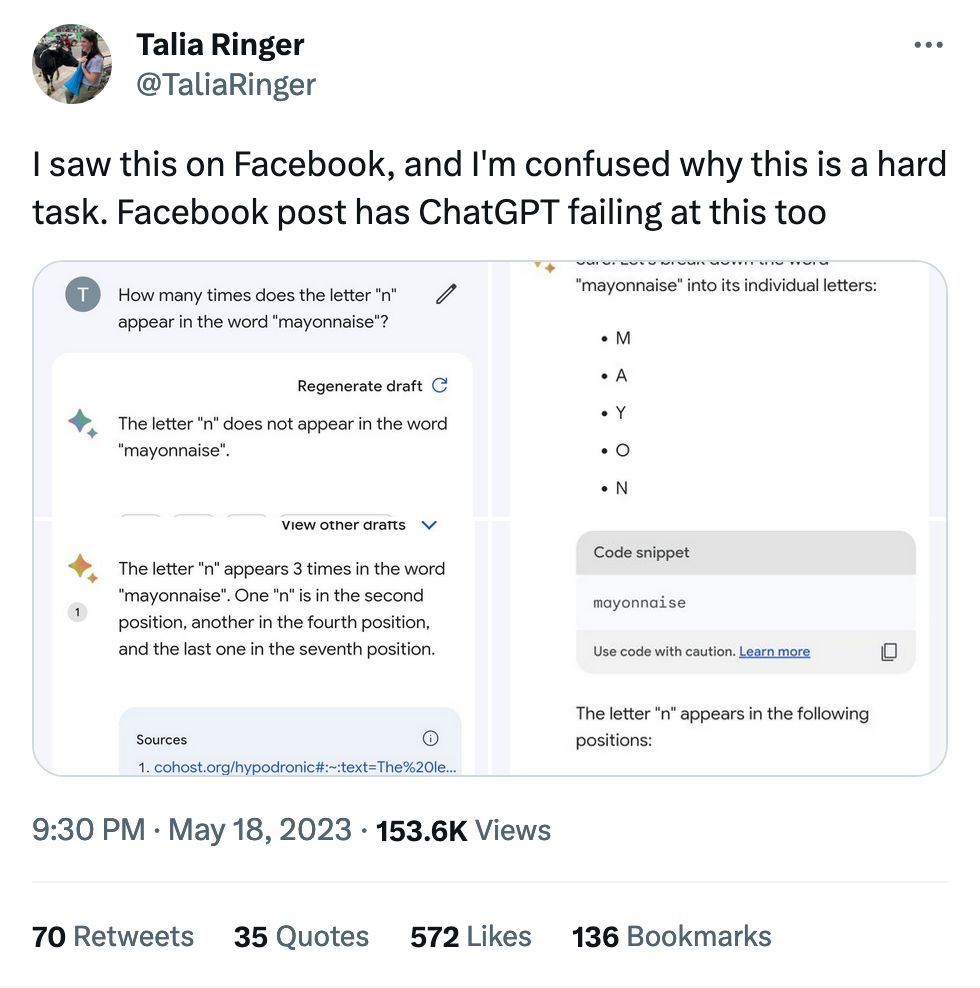
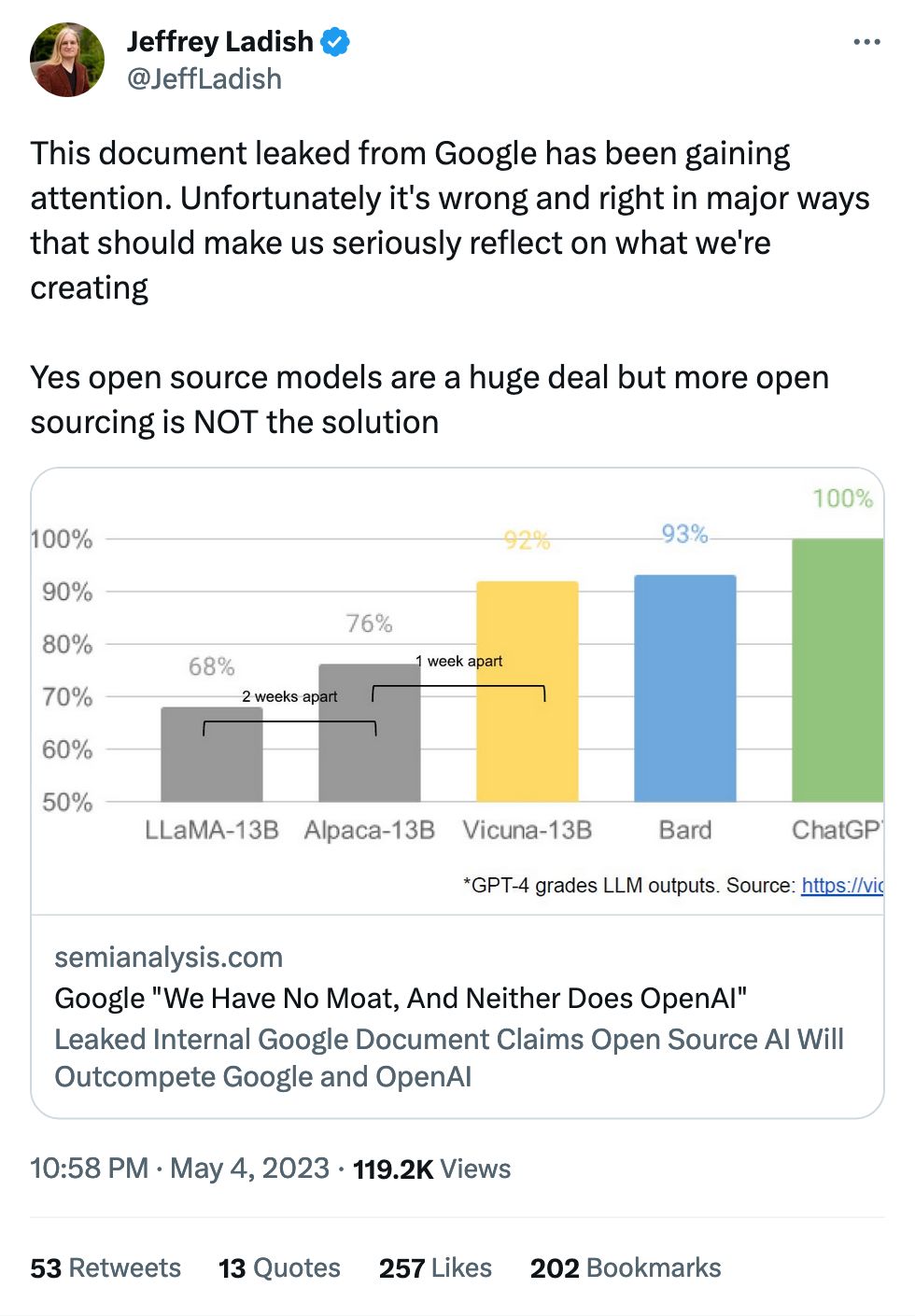
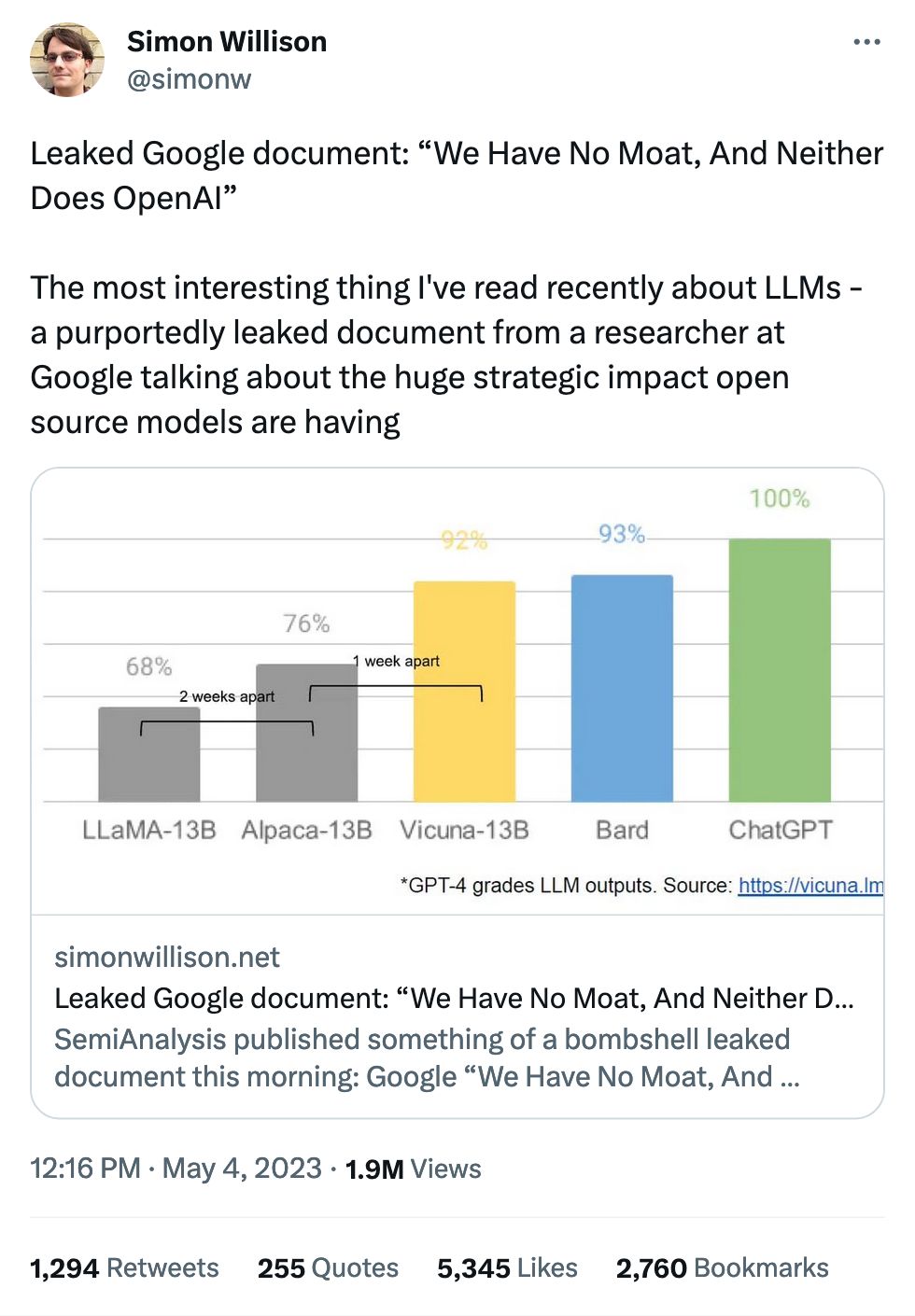
A "moat" is what prevents your clients from switching to another product.
As it stands in the immediate moment, most workflows are "throw some text into a product, get some text back." As a result, the box you throw the text into doesn't really matter – GPT, LLaMA, Bard – the only different is the quality of the results you get back.
Watch how this evolves, though: LLMs are going to add in little features and qualities that make it harder to jump to the competition. They might make your use case a little easier in the short term, but anything other than text-in text-out builds those walls a little higher.