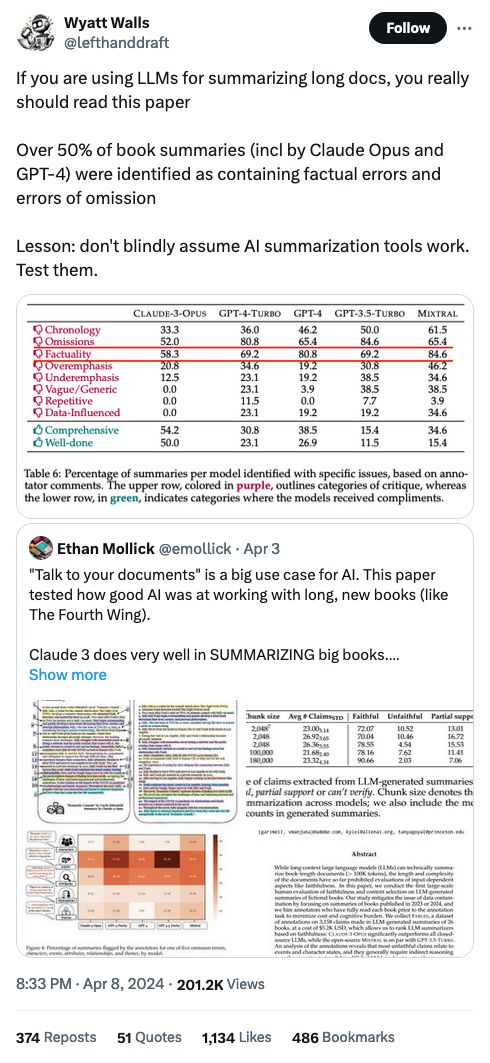
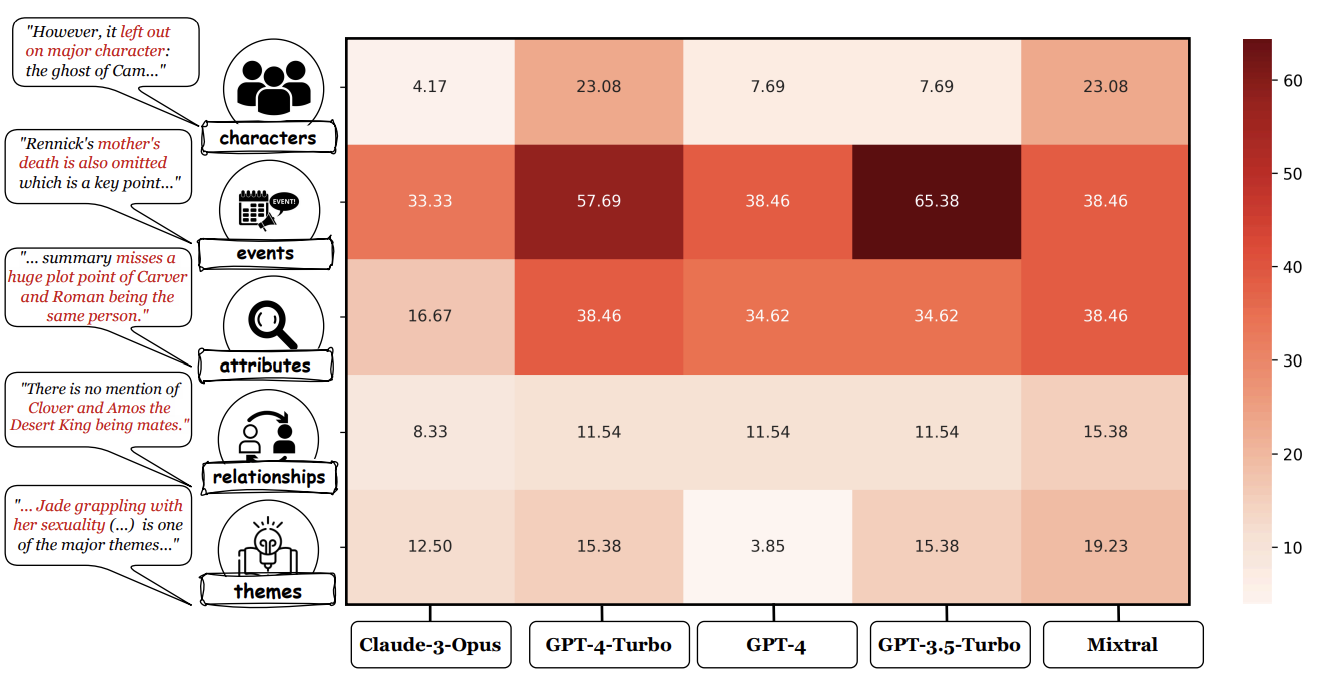
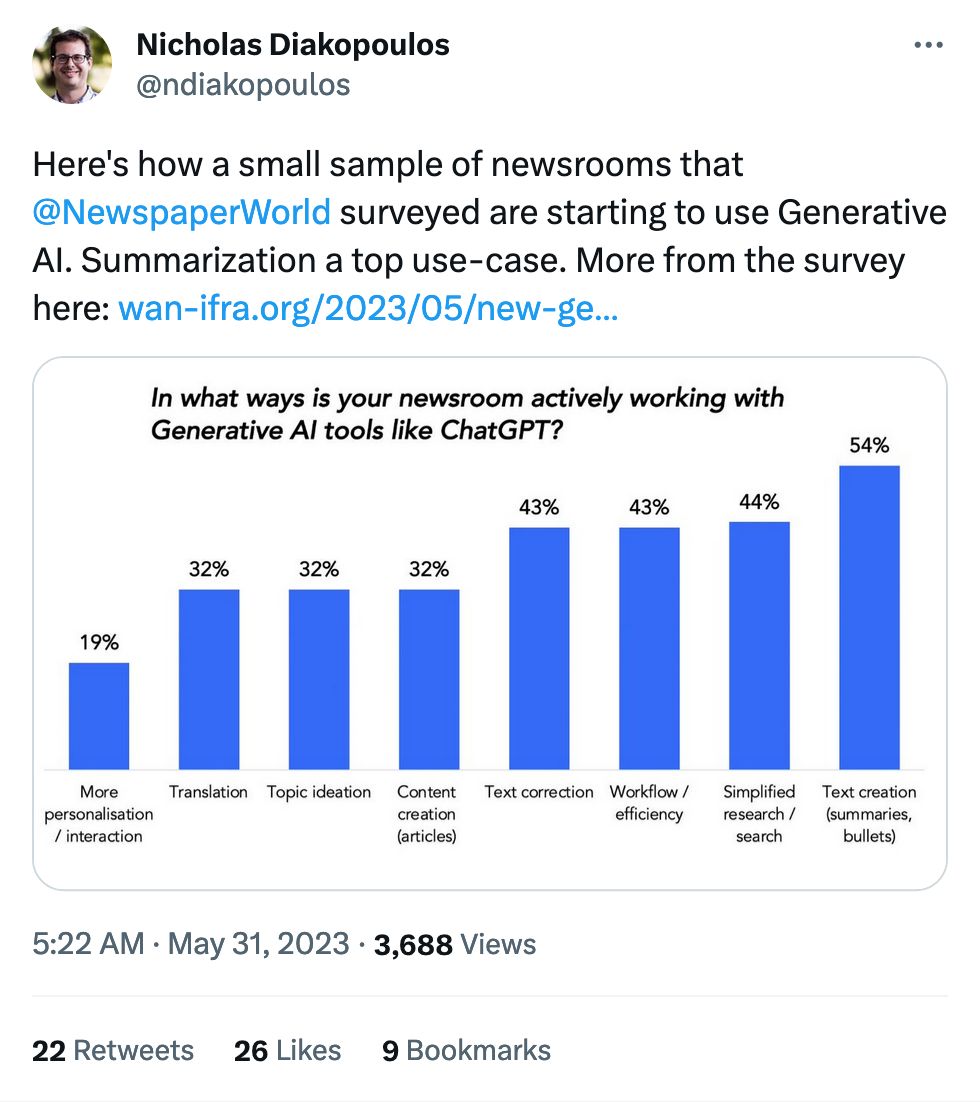
The link itself is super boring, but the comments are great: a ton of people arguing about whether or not LLM-based question-and-answer over documents works at all (especially with SEC filings and other financial docs).
- Shortcomings of text embeddings to return relevant documents
- Inability of LLMs to actually figure out what's interesting
I think the largest issue with summarization/doc-based Q&A is that when reading we as people bring a lot of knowledge to the table that is not just rearranging the words in a piece of text. What's talked about or mentioned the most is not always what's most important. One commentor talking about a colleague using ChatGPT to summarize SEC filings:
The tidbit it missed, one of the most important ones at the time, was a huge multi year contract given to a large investor in said company. To find it, including the honestly hilarious amount, one had to connect the disclosure of not specified contract to a named investor, the specifics of said contract (not mentioning the investor by name), the amount stated in some finacial statement from the document and, here obviously ChatGPT failed completely, knowledge of what said investor (a pretty (in)-famous company) specialized in. ChatGPT did even mention a single of those data points.
...
In short, without some serious promp working, and including addditional data sources, I think ChatGPT is utterly useless in analyzing SEC filings, even worse it can be outright misleading. Not that SEC filings are increadibly hard to read, some basic financial knowledge and someone pointing out the highlights, based on a basic understanding of how those filings actually work are supossed to work, and you are there.
Another one lowers the hallucination rate and encourages human comprehension by converting a human prompt into code that is used to search the database and return the relevant info, instead of having the LLM read and report on the info itself.
I also love this one about a traditional approach that draws attention to the when being sometimes an additional flag to the what:
They received SEC filings using a key red flag word filter into a shared Gmail account with special attention for filings done on Friday night or ahead of the holidays.