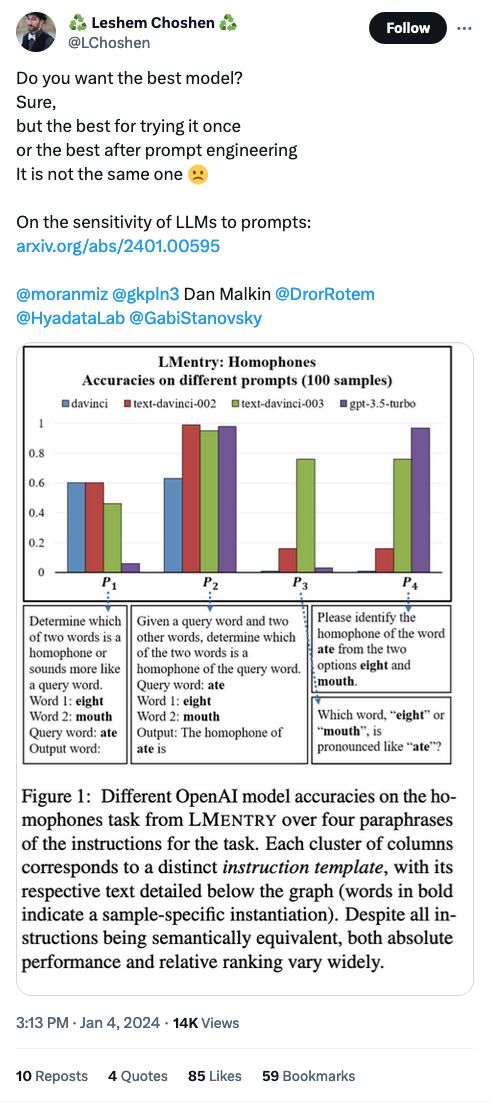
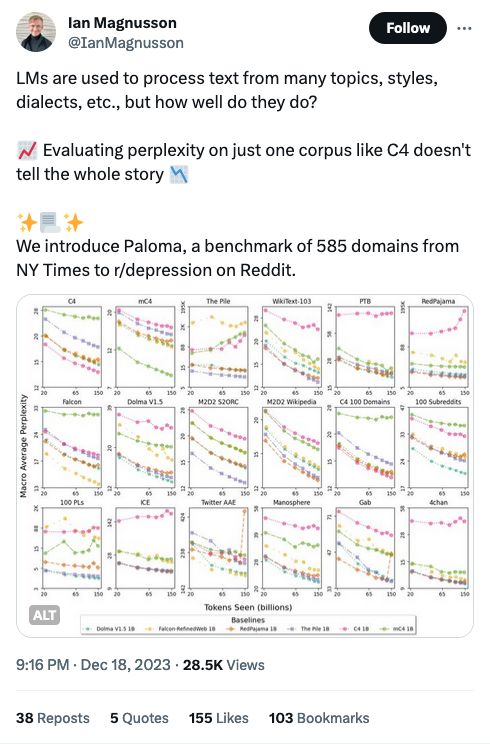
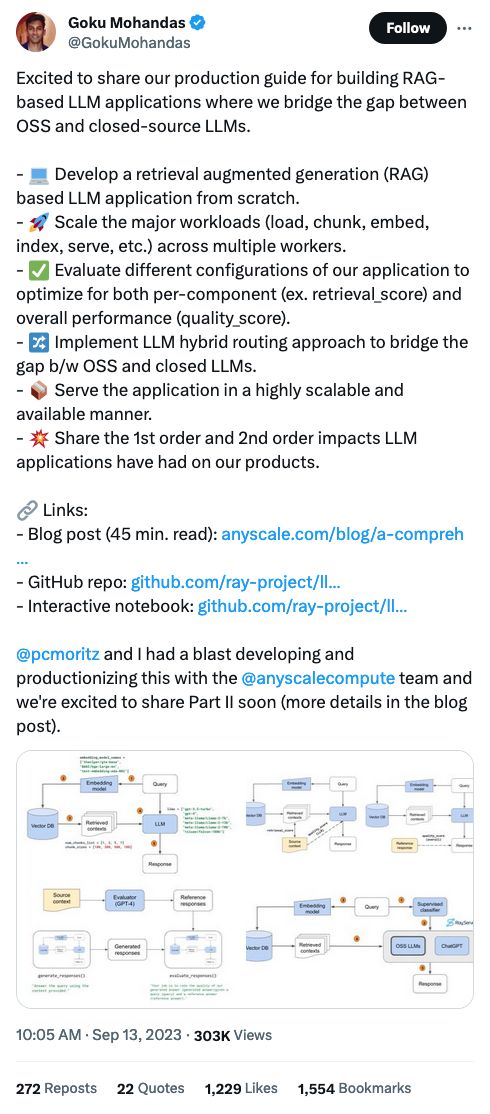
I think the way to think about prompt engineering is: what would the best teacher preface an instruction to a student with, if they really really wanted the student do do the best possible job?
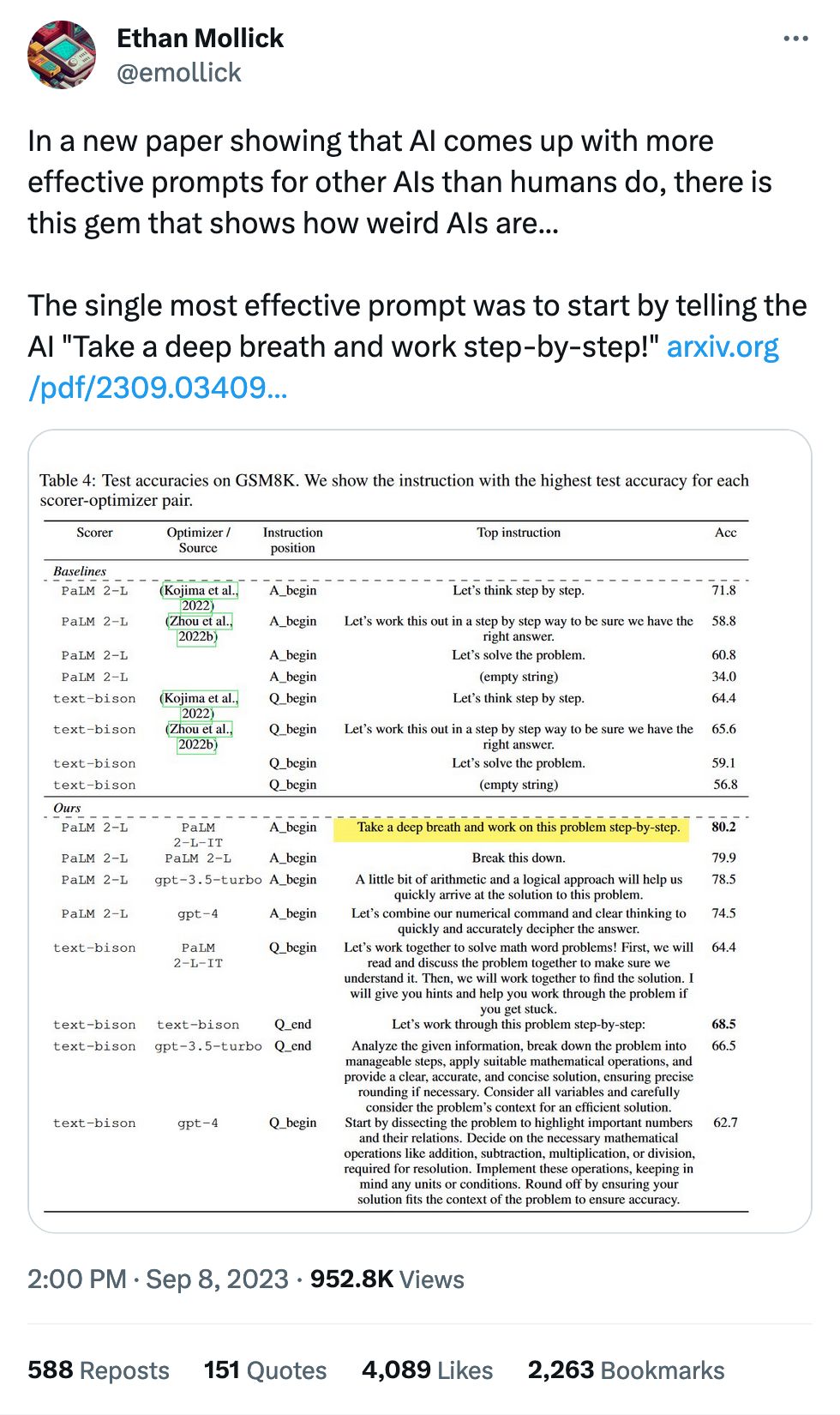
The worst performer, at 62.7%:
Start by dissecting the problem to highlight important numbers and their relations. Decide on the necessary mathematical operations like addition, subtraction, multiplication, or division, required for resolution. Implement these operations, keeping in mind any units or conditions. Round off by ensuring your solution fits the context of the problem to ensure accuracy.
That is obviously an awful way to start a lesson or a test. Even if someone knows the answer they're going to lose their minds!
The best performer, at 80.2%:
Take a deep breath and work on this problem step-by-step.
So relaxing, so kind, so guaranteed to ensure high performance.
Large Language Models as Optimizers: Paper here