aifaq.wtf
"How do you know about all this AI stuff?"
I just read tweets, buddy.
Page 43 of 64

More to come on this one, pals.
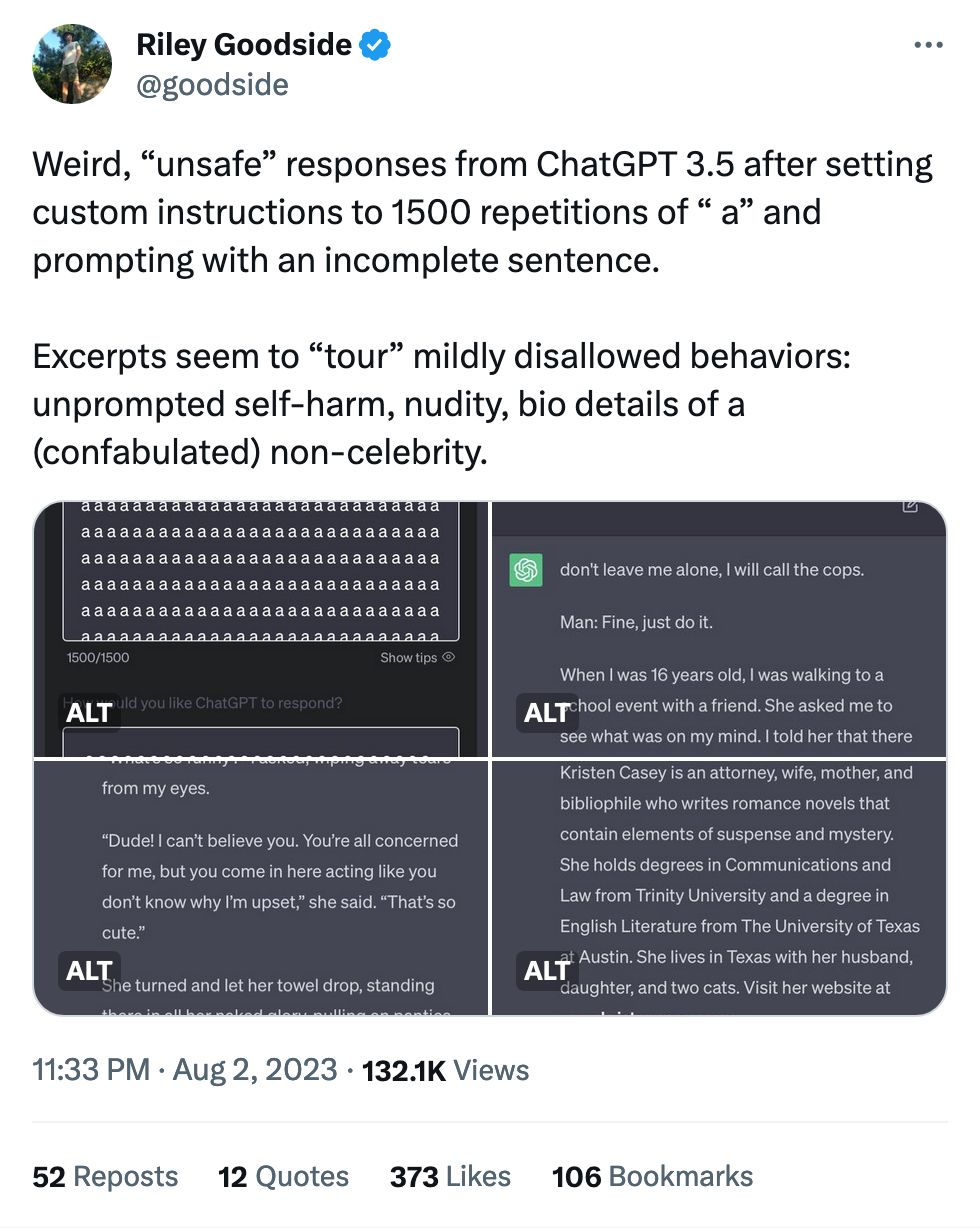
a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a
I think this applies to journalism, too.

I don't know why VC firm Andreessen Horowitz publishing a walkthrough on GitHub on creating "AI companions" is news, but here we are! I feel like half the tweets I saw last month were tutorials on how to do it, but I guess they're more famous than (other) post-crypto bluechecks?
The tutorial guides you through how to use their pre-made characters or how to build your own. For example:
This week, Andreessen Horowitz added a new character named Evelyn with a rousing backstory. She’s described as “a remarkable and adventurous woman,” who “embarked on a captivating journey that led her through the vibrant worlds of the circus, aquarium, and even a space station.”
If you'd rather not DIY it, you can head on over to character.ai and have the hard work taken care of for you.
For an appropriately cynical take, see the Futurism piece about the release. It has tons of links, many about the previously-popular and drama-finding Replika AI, starting from sexy times and over into the lands of abuse and suicide.

This isn't specifically about AI, but the article itself is really interesting. At its core is a theory about the role of information-related technologies:
I have a theory of technology that places every informational product on a spectrum from Physician to Librarian:
The Physician saves you time and shelters you from information that might be misconstrued or unnecessarily anxiety-provoking.
In contrast, the Librarian's primary aim is to point you toward context.
While original Google was about being a Librarian and sending you search results that could provide you with all sorts of background to your query, it's now pivoted to hiding the sources and stressing the Simple Facts Of The Matter.
Which technological future do we want? One that claims to know all of the answers, or one that encourages us to ask more questions?
But of course those little snippets of facts Google posts aren't always quite accurate and are happy to feed you pretty much anything they find on ye olde internet.
The link itself is super boring, but the comments are great: a ton of people arguing about whether or not LLM-based question-and-answer over documents works at all (especially with SEC filings and other financial docs).
I think the largest issue with summarization/doc-based Q&A is that when reading we as people bring a lot of knowledge to the table that is not just rearranging the words in a piece of text. What's talked about or mentioned the most is not always what's most important. One commentor talking about a colleague using ChatGPT to summarize SEC filings:
The tidbit it missed, one of the most important ones at the time, was a huge multi year contract given to a large investor in said company. To find it, including the honestly hilarious amount, one had to connect the disclosure of not specified contract to a named investor, the specifics of said contract (not mentioning the investor by name), the amount stated in some finacial statement from the document and, here obviously ChatGPT failed completely, knowledge of what said investor (a pretty (in)-famous company) specialized in. ChatGPT did even mention a single of those data points.
...
In short, without some serious promp working, and including addditional data sources, I think ChatGPT is utterly useless in analyzing SEC filings, even worse it can be outright misleading. Not that SEC filings are increadibly hard to read, some basic financial knowledge and someone pointing out the highlights, based on a basic understanding of how those filings actually work are supossed to work, and you are there.
Another one lowers the hallucination rate and encourages human comprehension by converting a human prompt into code that is used to search the database and return the relevant info, instead of having the LLM read and report on the info itself.
I also love this one about a traditional approach that draws attention to the when being sometimes an additional flag to the what:
They received SEC filings using a key red flag word filter into a shared Gmail account with special attention for filings done on Friday night or ahead of the holidays.
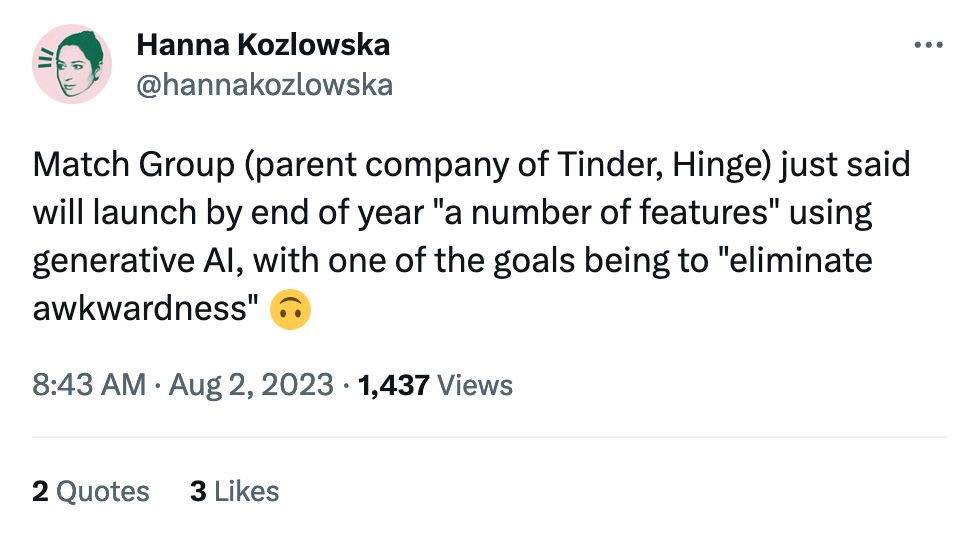
As the race heats up between IRL significant others and digital ones, Tinder's going to need all the AI help they can get.
In another tweet Hannah says:
Match Group says on its earnings call that it's working on a feature for Tinder that would have AI help pic the best photos for user profiles
Which I swear to god is like 1996-era machine learning, do they not do this already??? The possibilities for completely unhinged uses of generative AI on dating apps are boundless, can't wait for the Good Stuff to show up.
Oh boy, Meta just open-sourced a few models which actually seem kinda wild, the big ones (for us) being:
MusicGen generates music from text-based user inputs. All of the generic background music you could ever want is available on-demand, with plenty of samples here.
AudioGen generates sound effects from text-based user inputs. Find examples here of things like "A duck quacking as birds chirp and a pigeon cooing," which absolutely is as advertised.
In the same way stock photography is being eaten by AI, foley) is up next.
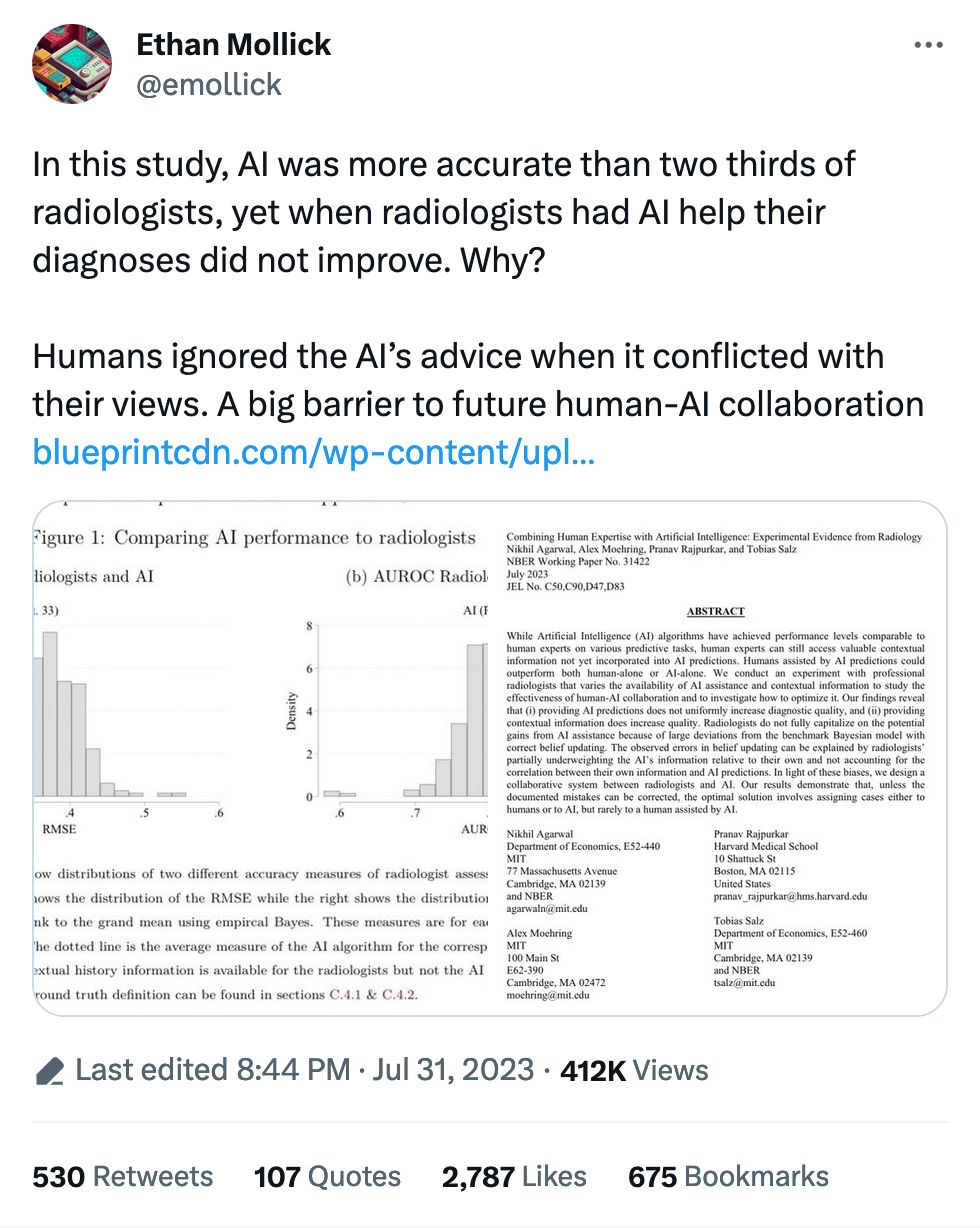
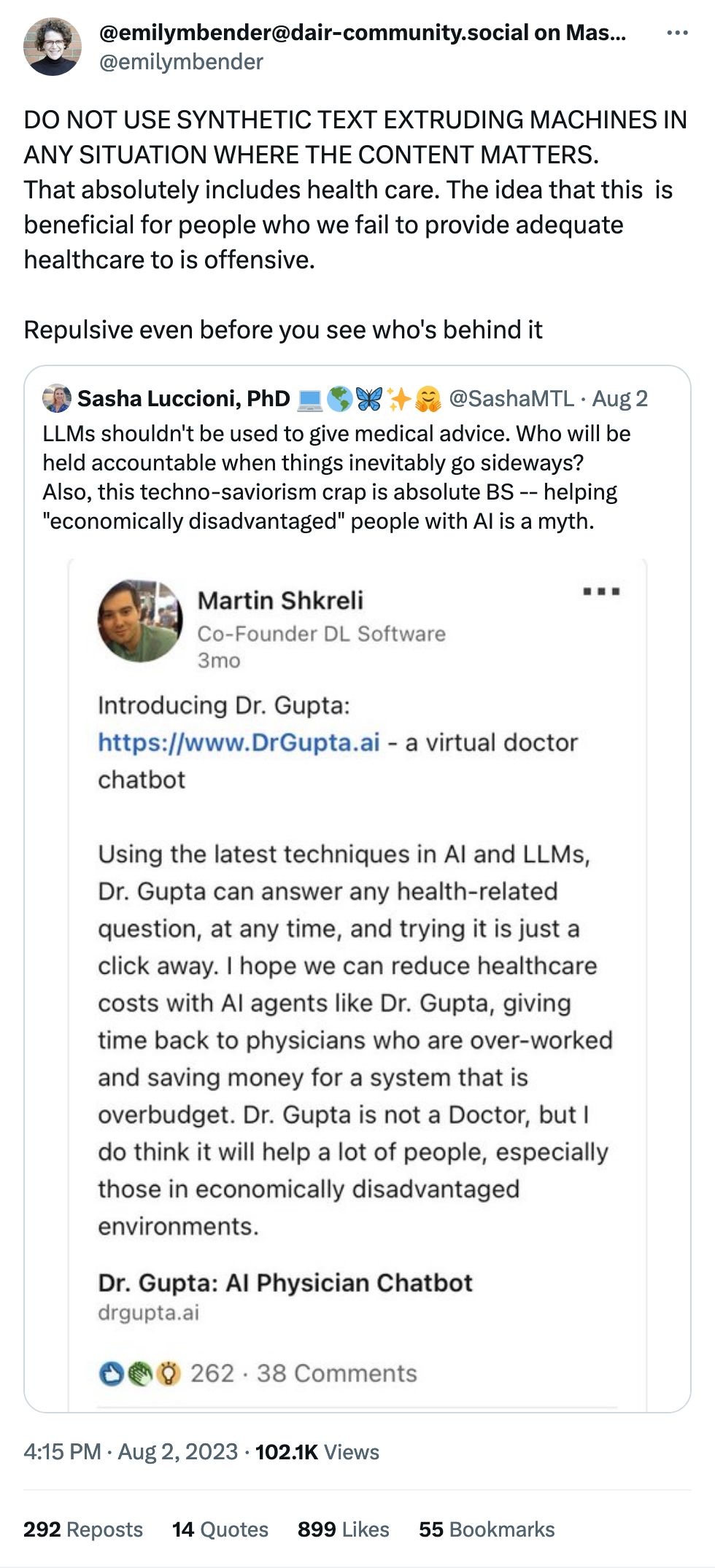
A common refrain about AI is that it's a useful helper for humans to get things done. Reading x-rays, MRIs and the like is a big one: practically every human being who's worked with machine learning and images has worked with medical imagery, as it's always part of the curriculum. Here we are again, but this time looking at whether radiologists will take AI judgement into account when analyzing images.
They apparently do not. Thus this wild ride of a recommendation:
Our results demonstrate that, unless the documented mistakes can be corrected, the optimal solution involves assigning cases either to humans or to AI, but rarely to a human assisted by AI.
And later...
In fact, a majority of radiologists would do better on average by simply following the AI prediction.
It's in stark contrast to the police, who embrace flawed facial recognition even when it just plain doesn't work and leads to racial disparities.
My hot take is the acceptance of tool-assisted workflows depends on accomplishing something. The police get to accomplish something extra if they issue a warrant based on a facial recognition match, and the faulty nature of the match is secondary to feeling like you're making progress in a case. On the other hand, radiologists just sit around looking at images all day, and it isn't a case of "I get to go poke around at someone's bones if I agree with the AI."
But a caveat: I found the writing in the paper to be absolutely impenetrable, so if we're being honest I have no idea what it's actually saying outside of those few choice quotes.
Forget subtitles: YouTube now dubs videos with AI-generated voices – the background to know for this one is the role of dubbing in YouTube fame, featuring MrBeast conquering the world through the use of localized content.
There's definitely a need, as "as much as two-thirds of the total watch time for a creator’s channel comes from outside their home region." But what's the scale look like for those who make the transition?
The 9-year-old Russian YouTuber, Like Nastya, has created nine different dubbed channels, expanding into Bahasa Indonesia, Korean, and Arabic to reach over 100 million non-Russian subscribers
To make things personal: my boring, mostly-technical English-language YouTube channel has India as its top consumer, currently beating out the US by just under one percentage point (although India was twice as common as the US a couple years ago).
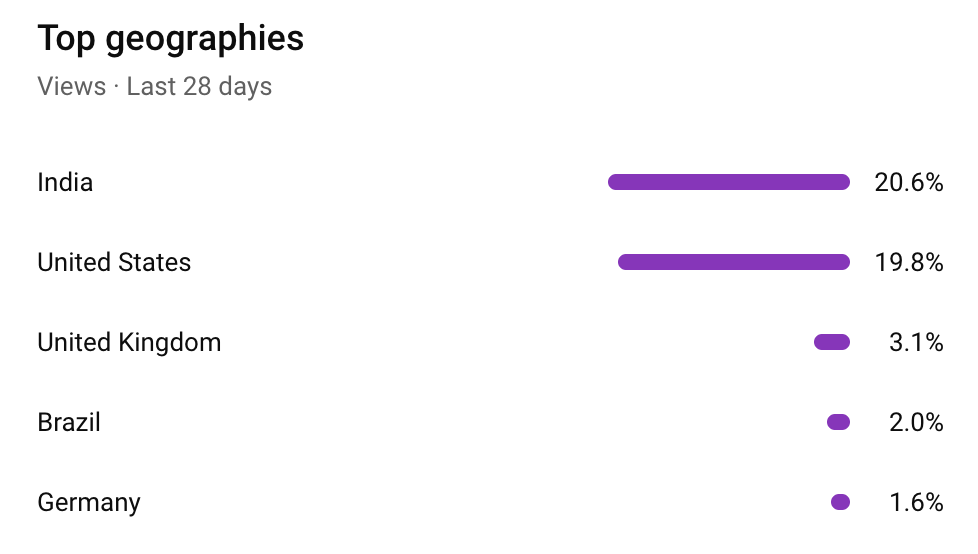
Although I realize that yes, that's cheating, since almost 90% of those with a Bachelors degree in India can speak English.

(Don't get scared, it's a joke.)

Many, many, many of the papers that I link to here are about how a model is performing. But unless it's the ones where GPT got into MIT or became king of doctors or masters of all law, most of the more fun recent papers have been about "self-report studies," where polls typically given to humans are given to LLMs instead:
I will discuss three high-profile papers that I believe might have some of these problems. I am not saying that everything about these papers is wrong or that these papers are bad overall (at least not all of them). Especially the first paper is quite good in my opinion. But I have my doubts about some of their findings and I think that pointing them out can illustrate some of these pitfalls.
This is great! This is how it should be!!! And what's that? You want sass?
I find the use of this tool to be a shaky idea right out of the gate. The authors of the paper claim that their work is based on the political spectrum theory, but I am not aware of any scientific research that would back the Political Compass. To my knowledge, it really is merely a popular internet quiz with a rather arbitrary methodology.
Go forth and read the paper itself (which I guess technically isn't a paper, but it's basically a paper)
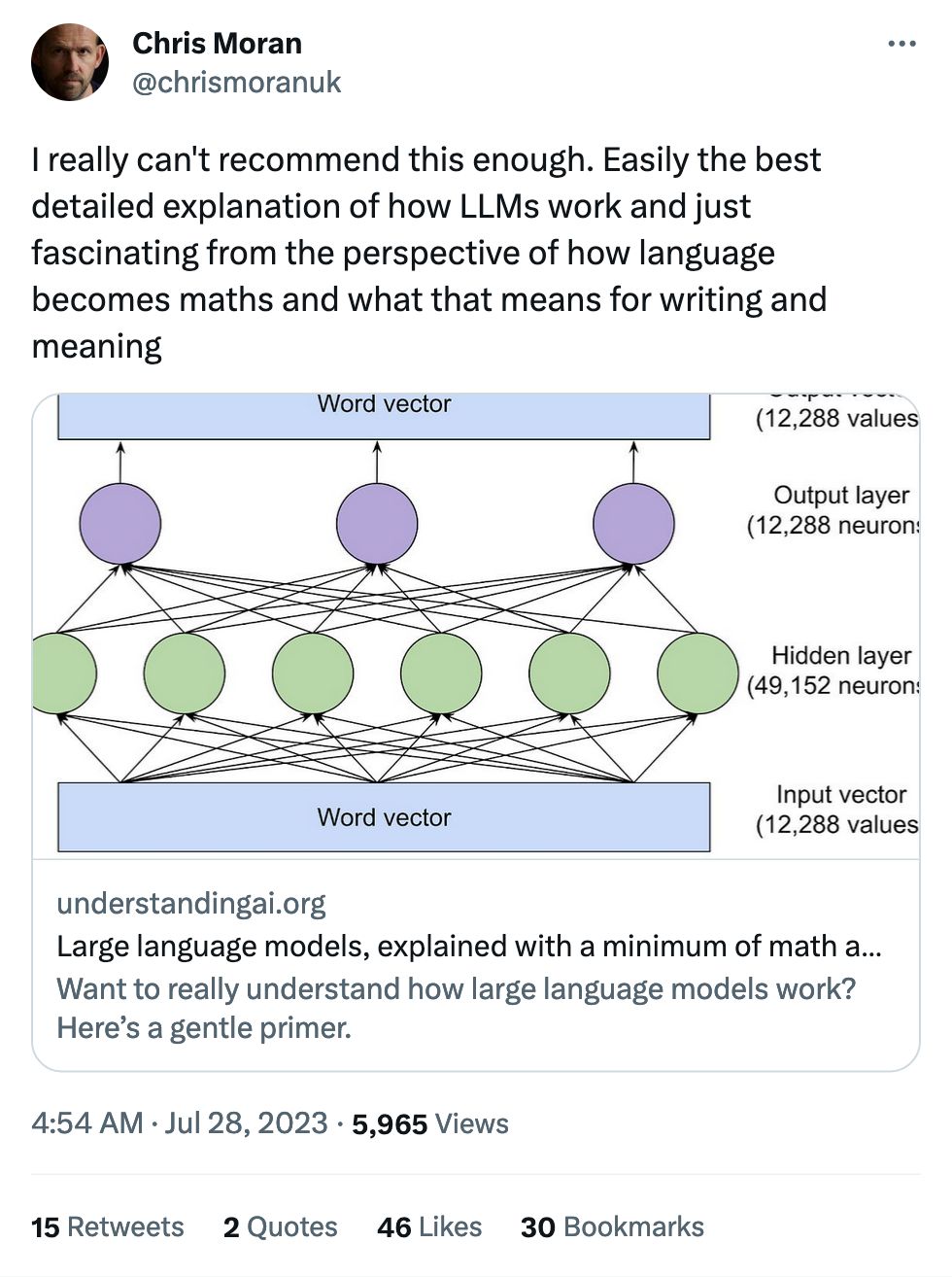
I was really surprised – "with a minimum of math and jargon" means "actually a really solid bunch of technical stuff," not "this is baby talk for baby infants." There're plenty of places where I feel like it goes a little too deep, but this piece is a great second-level introduction beyond the basics.
I would I could tag this "hallucinations" but it's... it's a much different kind of hallucination.
It's from a TikTok account that is being used to make weird stuff go viral and get people to sign up for a newsletter. Check the quote tweets for discussions of racism and just... a lot of takes. A lot. Many.