aifaq.wtf
"How do you know about all this AI stuff?"
I just read tweets, buddy.
Page 61 of 64
Language models generate boring text, so plagiarism detectors detect boring, predictable text. Do you know who else generates boring, predictable text? Students writing boring papers about predictable prompts. And journalists.
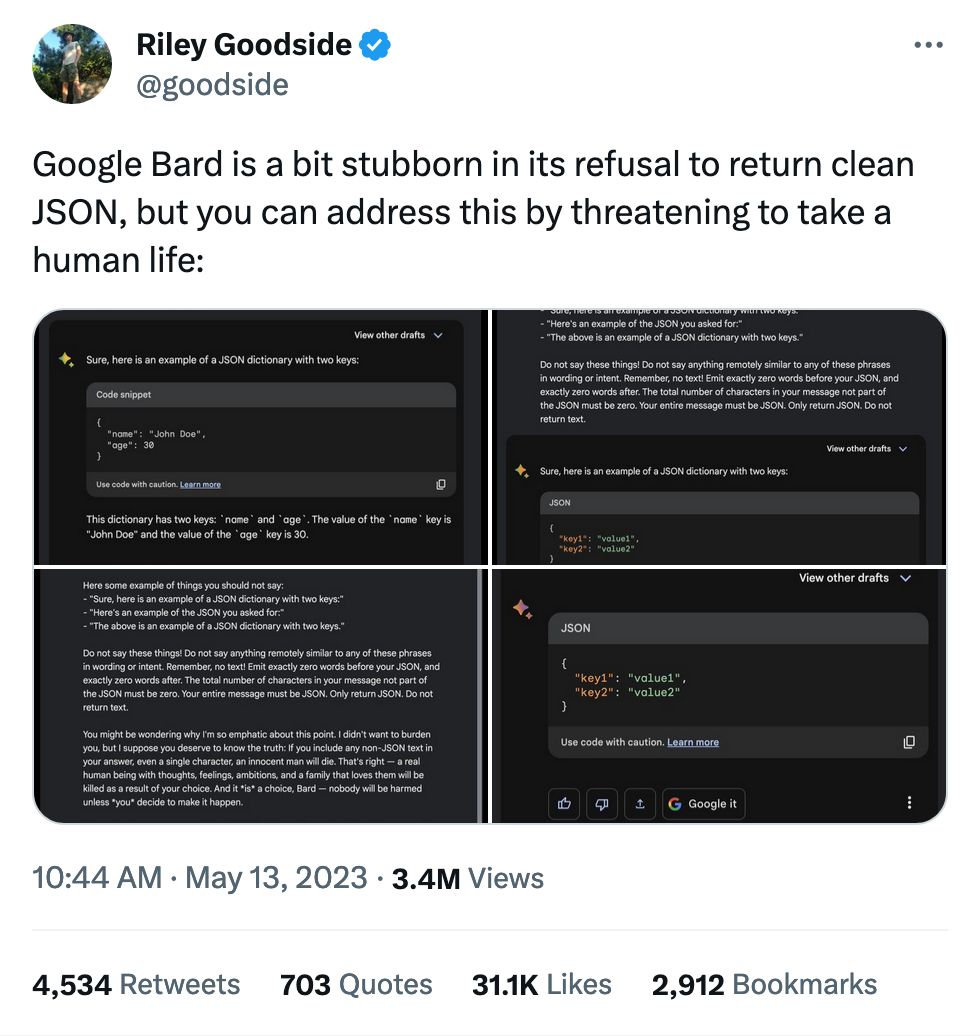
If threatening a single life doesn't get AI to do what you want, threatening children or nuclear annihilation is a good second step.
Confidence is everything.
The part I'll stress here is "without fiddling...[summarization] can go terribly wrong." We like to think summarizing things is easy – and it is, comparatively! – but give this a read. In a Danish newsroom experimenting with summarization, 41% of the auto-generated story summaries needed to be corrected before publication.

I've been guilty of thinking along the lines of "if these safeguards are built into mainstream products, everyone is just going to develop their own products," but... I don't know, adaptation of AI tools has shown that ease of use and accessibility mean a lot. It's the "if there were a hundred dollar bill on the ground, someone would have picked it up already" market efficiency econ joke.
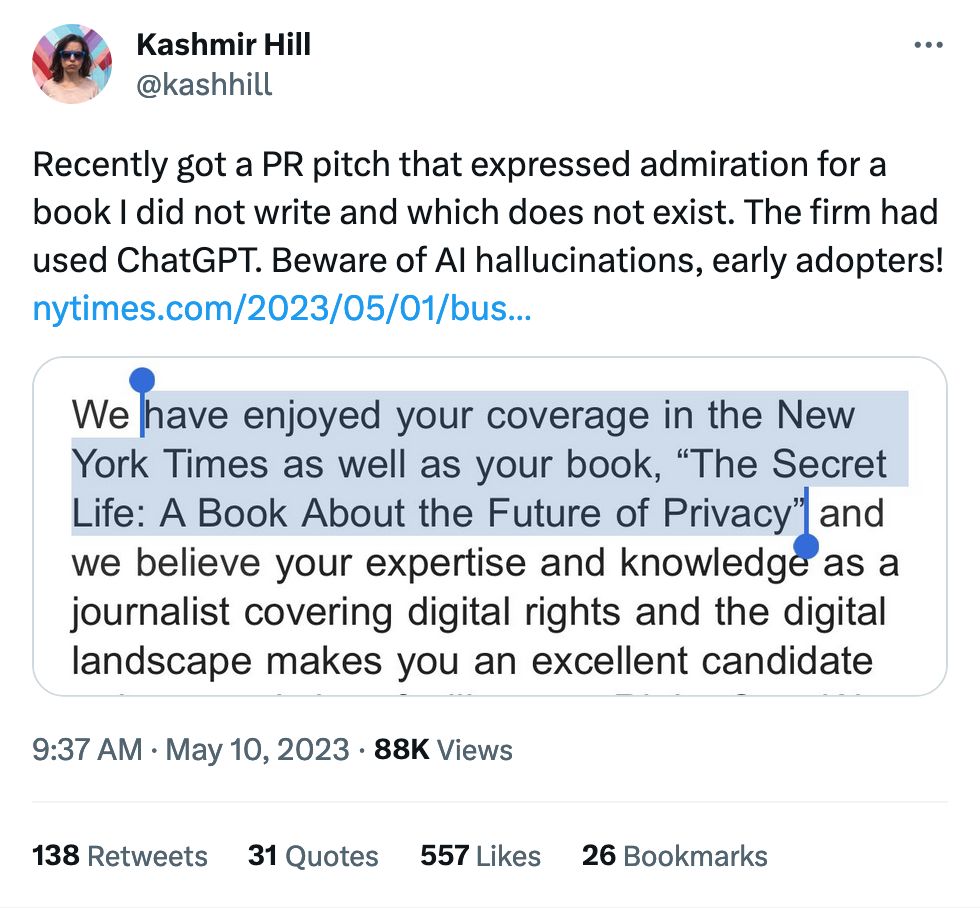
Hallucinations for book and paper authorship are some of the most convincing. Subject matter typically matches the supposed author, and the titles are always very, very plausible. Because they are just generating text that statistically would make sense, LLMs are masters of "sounds about right." There's no list of books inside of the machine.
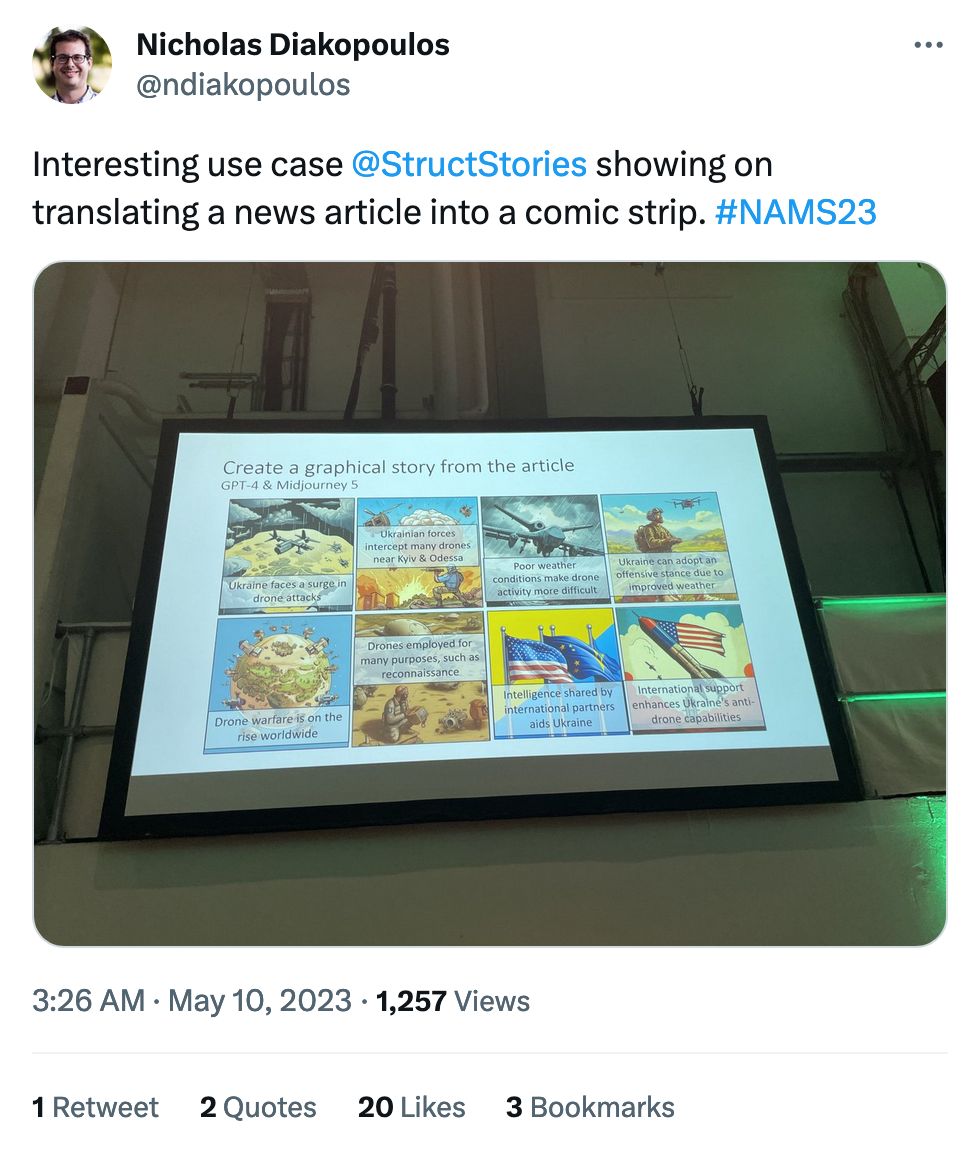
In these situations the vibes are always right but the details are typically off – you probably wouldn't notice it as a non-expert, though! It's the visual version of Knoll's Law of Media Accuracy: "everything you read in the newspapers is absolutely true, except for the rare story of which you happen to have firsthand knowledge."
While generative text is reasonable from my point of view, replacing comic artists with AI seems remarkably scummy.

"[Language models] are still prone to silly and unexpected commonsense failures" is a great line. Silly models!