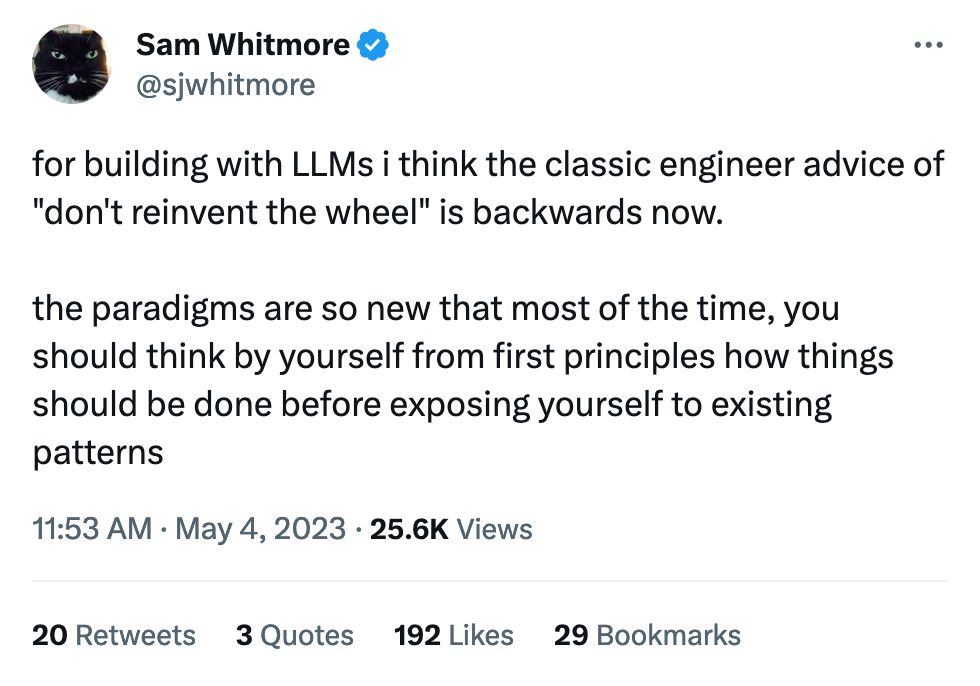
aifaq.wtf
"How do you know about all this AI stuff?"
I just read tweets, buddy.
Page 63 of 64

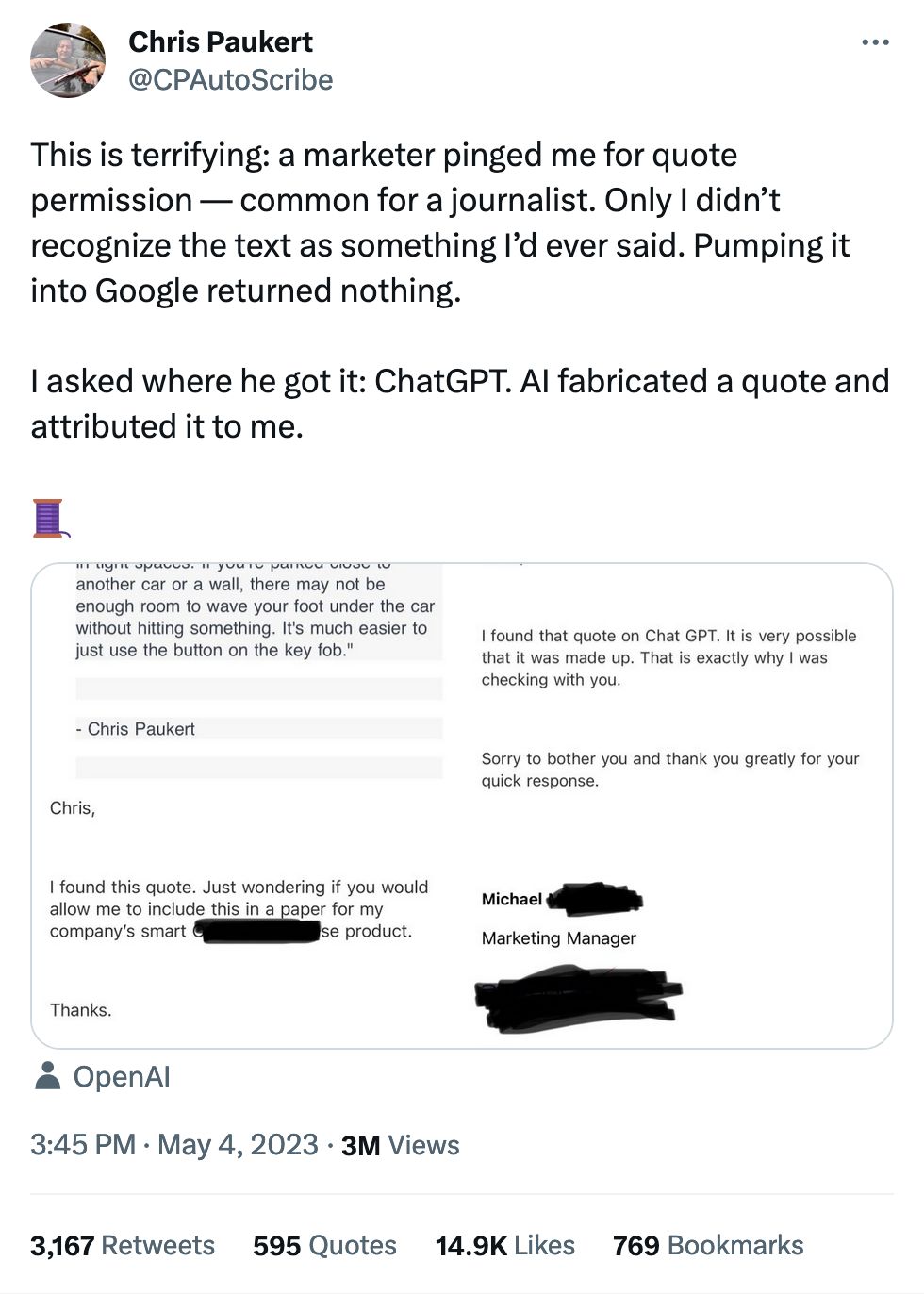
At some point I just stopped collecting tweets like this, there were just too many.
How regulation functions:
if the only additional guardrail you support is that every time thing X occurs, it goes to the courts, then the reasonable bad actor only needs to make the rest of their operation efficient enough to profit before they go to trial.


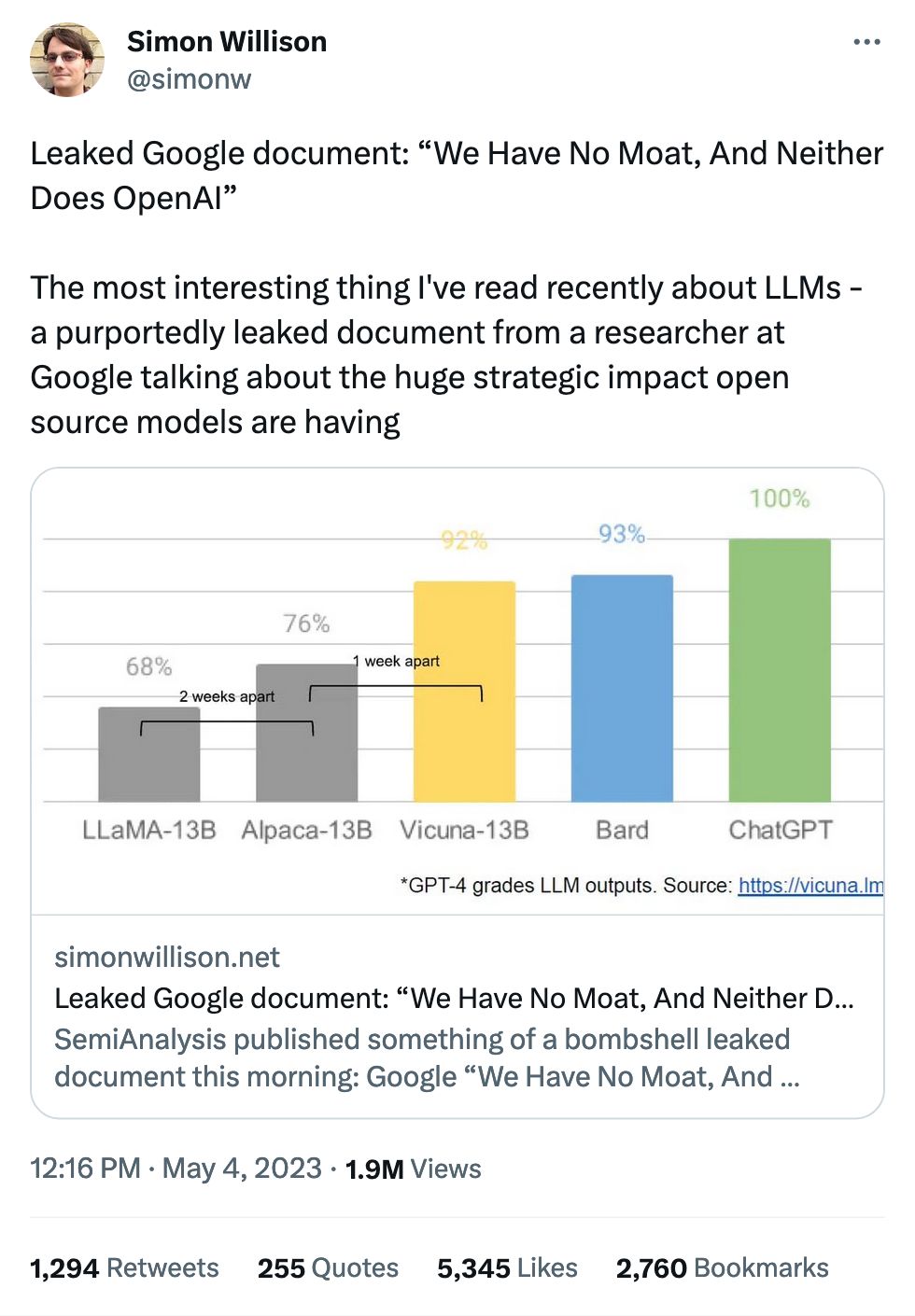
A "moat" is what prevents your clients from switching to another product.
As it stands in the immediate moment, most workflows are "throw some text into a product, get some text back." As a result, the box you throw the text into doesn't really matter – GPT, LLaMA, Bard – the only different is the quality of the results you get back.
Watch how this evolves, though: LLMs are going to add in little features and qualities that make it harder to jump to the competition. They might make your use case a little easier in the short term, but anything other than text-in text-out builds those walls a little higher.

We're impressed by the toy use cases for LLMs because they're things like "write a poem about popcorn" and the result is fun and adorable. The problem is when you try to use them for Real Work: it turns out LLMs make things up all of the time! If you're relying on them for facts or accuracy you're going to be sorely disappointed.
Unfortunately, it's easy to stop at the good "wow" and don't not get deep enough to get to the bad "wow." This tweet should be legally required reading for anyone signing off on AI in their organization.
The reason to read Hacker News on AI is much less to learn anything and much more to learn what other people are thinking. The passion, the intensity, the fervor!!!
Top-voted comment is really doing its best to coax anyone and everyone out of their holes:
I think the author is far too pessimistic about the capabilities of ML...However - the level of Silicon Valley Bro VC funded hype is totally out of this world.
And (roughly) immediately eveything devolves into arguments about self-driving cars. Rightly so?
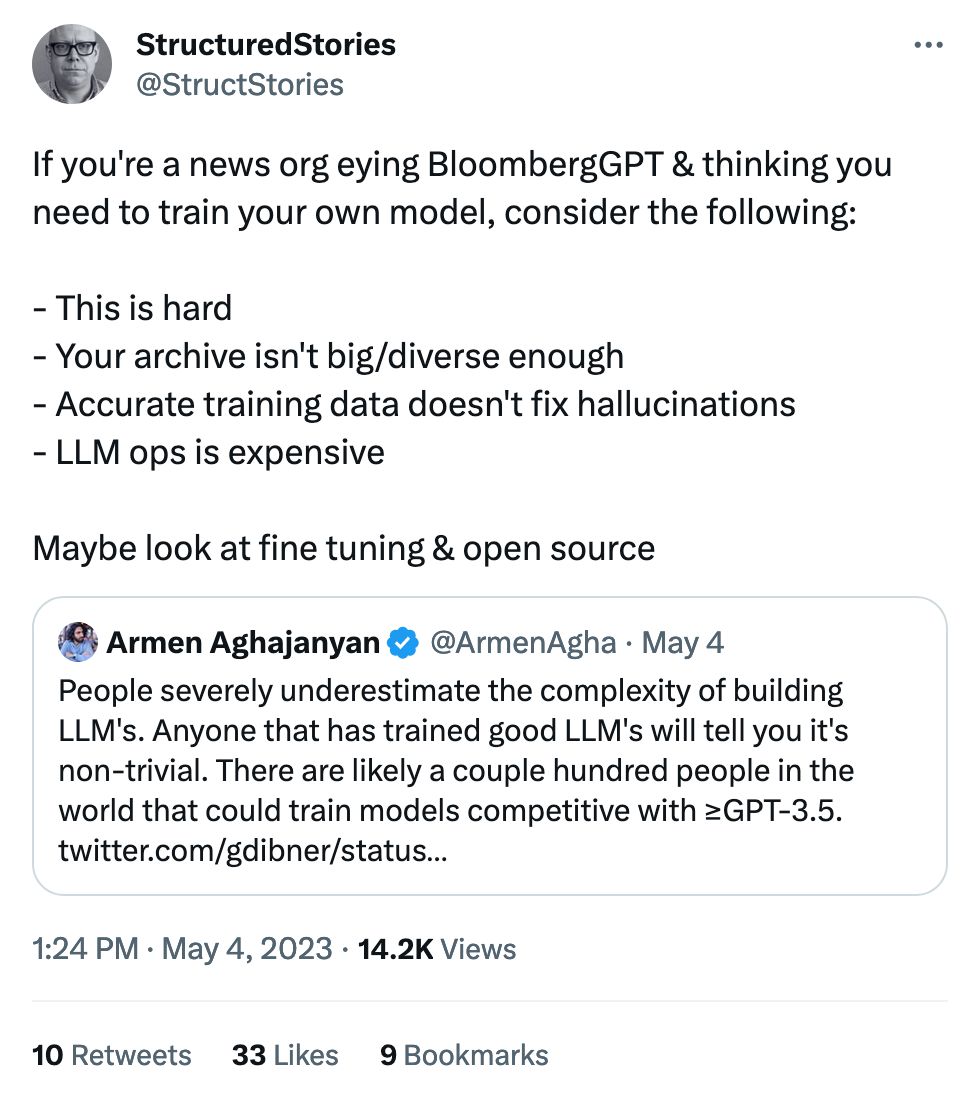
Not that I know the details, but I have my doubts that BloombergGPT was even worth it. I think "maybe look at" is a little too gentle – if you think you need your own model, you don't.
Prompt engineering and even somewhat thoughtful engineering of a pipeline should take care of most of your use cases, with fine-tuning filling in any gaps. The only reason you'd train from scratch is if you're worried about the copyright/legal/ethical implications of the data LLMs were trained on – and if you're worried about that, I doubt you have enough data to build a model.